Apache Spark 是現今處理巨量資料(large-scale data)分析、資料處理、機器學習(machine learning)的主流叢集運算框架之一,其主打簡單、快速、可擴充(scalable)、統一介面(unified) 4 大特點,更支援多種語言(Python, Java, R, SQL)可供靈活選擇運用。
Spark 採用的是 In-memory 運算技術,運算的資料存在於記憶體之中,相對於使用硬碟等儲存媒介的運算框架(例如 Apache Hadoop)而言, Spark 具有運算速度的優勢。
此外,除了提供核心運算功能的 Spark Core, Apache Spark 更在其基礎上衍生 Spark SQL, Spark Streaming, MLlib, GraphX 四大功能:
- Spark SQL - 支援以 SQL 對資料進行操作、運算
- Spark Streaming - 讓 Spark 能夠處理串流(streaming)形式的資料
- MLlib - 增加機器學習(machine learning)的相關函式庫(library),讓開發者得以利用 Apache Spark 進行機器學習相關的運算
- GraphX - 支援圖論(graph theory)相關的運算,像社群網絡(social network)相關數據分析就適合使用 GraphX 進行運算
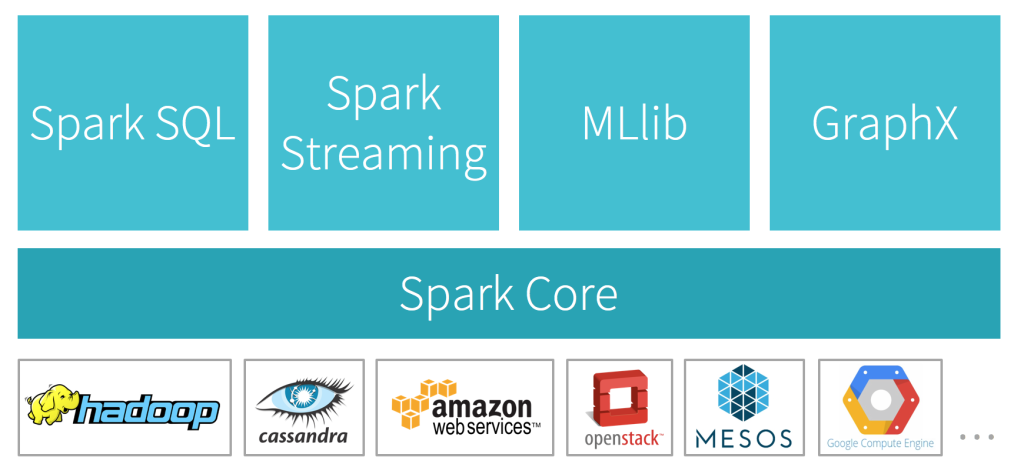 引用自 https://databricks.com
引用自 https://databricks.com
綜觀來說,Apache Spark 是相當值得投資學習的一套運算框架。
本文將透過 Docker 以及 PySpark 為初學者提供接觸 Apache Spark 的一條捷徑。
Last updated on
Dec 16, 2022
in
Python 模組/套件推薦
, Python 程式設計 - 高階
by
Amo Chen
‐ 5 min read