零經驗也可的 PySpark 教學 - DataFrame part 1
上一篇 零經驗也可的 PySpark 教學 - 初體驗 ,我們透過 Docker 輕易地體驗到 PySpark 的功能,利用 PySpark 將 CSV 資料載入 DataFrame ,再將 DataFrame 轉成 temporary view 後,我們就能夠使用 SQL 對資料進行操作,過程相當輕鬆寫意。
不過 DataFrame 提供相當多的 API, 讓開發者能夠像操作 ORM(Object Relational Mapping) 一樣進行開發,可說是 PySpark 學習過程必須學會的一環,本篇將介紹更多關於 DataFrame 的相關操作,包含 SELECT, FILTER, JOIN, UNION 等常用的功能。
Last updated on Dec 16, 2022 in Python 模組/套件推薦 , Python 程式設計 - 高階 by Amo Chen ‐ 6 min read
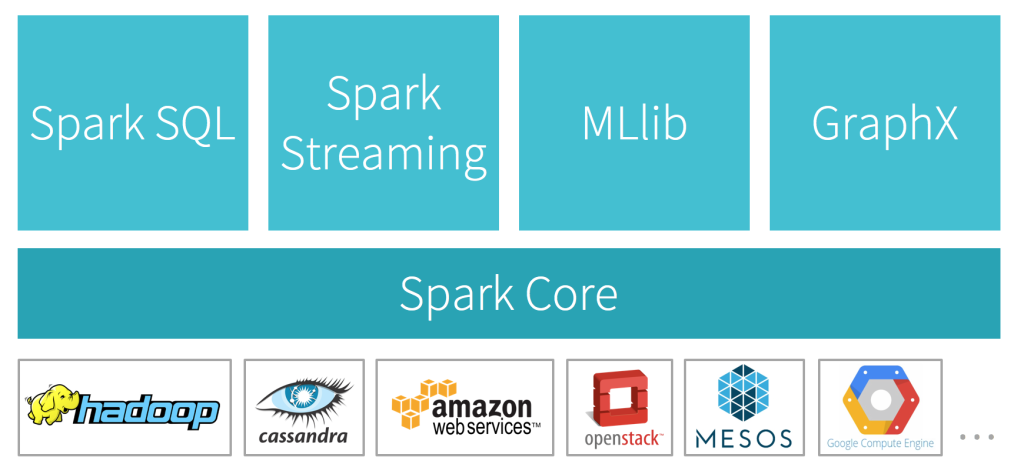 引用自 https://databricks.com
引用自 https://databricks.com