為計數而生 - Python Counter 類別
Posted on Apr 19, 2022 in Python 程式設計 - 初階 by Amo Chen ‐ 3 min read
Python collections 模組提供多個方便的類別(class)供開發者利用,其中 Counter 類別(dict 的子類別)可以應用在計數(counting)相關的場景:
本文將介紹 Counter 類別的使用方式,並比較其與 dict 與 defaultdict 之間的效能差異。
本文環境
- Python 3.7
Counter 類別介紹
一般做統計項目的計數(counting), 我們都會很直覺使用 dict (或稱字典)進行,例如以下利用 dict 統計單字(words)個數、 stopwords 個數、多少句子:
counters = {
"words": 123,
"stopwords": 4,
"sentences": 6,
}
使用 dict 進行統計時,不免都要判斷鍵值(key)是否已經存在於該字典中,如果不存在就指定個預設值,如果已經存在就按照需求增減計數,例如以下形式的程式碼:
if key in counters:
counters[key] += 1
else:
counters[key] = 1
除了上述檢查 key 是否存在的方法外,也可用 setdefault() 為不存在的 key 設定預設值,例如以下範例程式碼使用 setdefault() 之後,就不再需要用 if 檢查 key 是否存在:
counters.setdefault(key, 0)
counters[key] += 1
Counter 是在 Python 3.1 之後加入的新類別(class), 可以說集前述做法於一身,並進一步簡化的成果。使用 Counter 後,開發者們不需再檢查 key 是否存在字典中,也不需為 key 值設定預設值(直接預設為 0),因此使用上可以直接簡化為:
from collections import Counter
counters = Counter(
{
'words': 123,
'stopwords': 4,
'sentences': 6,
}
)
counters['words'] += 1
counters['new item'] += 1
也由於 Counter 繼承自 dict , 所以也能用與 dict 相同的方式進行走訪,例如:
from collections import Counter
counters = Counter(
{
'words': 123,
'stopwords': 4,
'sentences': 6,
}
)
for k, v in counters.items():
print(k, v)
Counter 類別也有內建一些實用的方法,像 most_common() 可以幫助我們取的前 n 大的 key 與 value, 並且遞減排序,或者 [例如以下範例取得 counters 中的前 3 大 key 與 value:
>>> counters.most_common(3) # TOP 3
[('words', 123), ('sentences', 6), ('stopwords', 4)]
Counter 類別接受帶入參數作為初始值,參數可以是 iterable, dict 甚至是 keyword arguments, 例如以下範例,其執行結果都是相同的:
counters = Counters({'a': 1, 'b': 2})
counters = Counter(['a', 'b', 'b'])
counters = Counters('abb')
counters = Counters(a=1, b=2)
Counter 也支援 + - 運算,加法會將 2 個 Counter 中所有的 key 合併,並對相同 key 的值進行加總:
>>> Counter(a=1, b=1) + Counter(a=1, b=1, c=1)
Counter({'a': 2, 'b': 2, 'c': 1})
而減法運算則僅對相同 key 的值進行相減,如果相減後值為 0, 則刪去該 key 值:
>>> Counter(a=3, b=1) - Counter(a=1, b=1, c=1)
Counter({'a': 2})
此外,Counter 也像 set() 一樣支援 | (Bitwise Or)與 & (Bitwise And) 2 種運算。
使用 | (Bitwise Or) 會留下 Counter 中每個 key 的最大值:
>>> Counter('abbb') | Counter('bcc')
Counter({'b': 3, 'c': 2, 'a': 1})
使用 & (Bitwise And) 則是只會留下 Counters 交集(intersection)部分的每個 key 的最小值:
>>> Counter('abbbc') & Counter('bcc')
Counter({'b': 1, 'c': 1})
執行效率比較(Benchmark)
最後比較一下使用 dict , defaultdict , Counter 的執行效率。
以下範例程式分別以 dict , defaultdict , Counter 計算長字串 A2Z1000 (a 到 z 重複 1000 次)中每個字元出現的次數,並用 Jupyter notebook 的 %timeit 衡量其執行時間:
from collections import Counter, defaultdict
A2Z1000 = ''.join(chr(i) for i in range(97, 123)) * 1000
def use_dict_to_count():
d = dict()
for c in A2Z1000:
d.setdefault(c, 0)
d[c] += 1
def use_default_dict_to_count():
d = defaultdict(int)
for c in A2Z1000:
d[c] += 1
def use_counter_to_count():
d = Counter()
for c in A2Z1000:
d[c] += 1
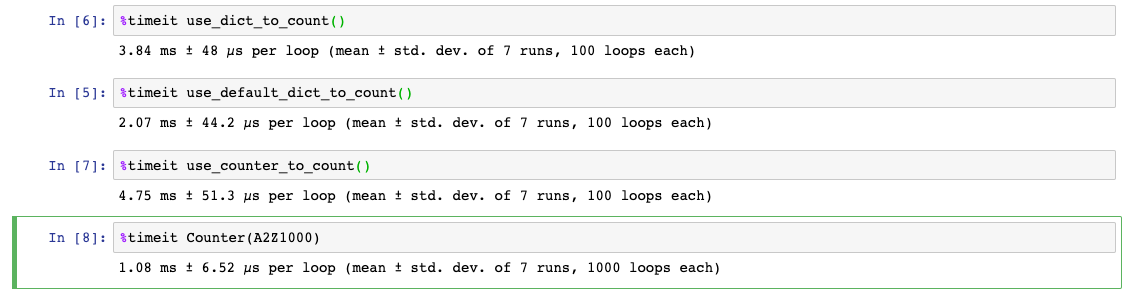
上述結果可以看到 use_counter_to_count() 比起單用 dict 以及 defaultdict 來的較慢。
但有趣的是當我們單純改用 Counter(A2Z1000) 時,效率反而變得極好!這是為什麼呢?
原來,初始化 Counter 實例(instance)時,如果傳進去的是 iterable, 那麼 Counter 會呼叫一個由 C 實作的 helper function - _count_elements, 該函式除了得益於 C 語言的效率之外,也減少很多 Python 天生物件化操作的耗費(overheads), 所以才會相對較快。
要改善 Counter 的效率的話,建議使用 Counter(iterable) 的方式進行計算之外,也可以呼叫 Counter 所提供的 update() 方法(該方法並不像 dict 與 defaultdict 是對 key 值進行覆蓋,而是加總),只要傳進去 iterable, 該方法也會呼叫 _count_elements 進行計算,因此 use_counter_to_count() 可以進一步改成以下形式,就能夠比 dict 與 defaultdict 更快:
def use_counter_to_count():
d = Counter()
d.update(A2Z1000)
以上,就是關於 Counter 類別的介紹啦!
Happy Coding!
References
https://github.com/python/cpython/blob/7acedd71dec4e60400c865911e8961dbb49d5597/Lib/collections/init.py#L534
https://docs.python.org/3/library/collections.html#collections.Counter