零經驗也可的 PySpark 教學 - 資料輸出 (DataFrame writer)
Posted on Feb 6, 2023 in Python 模組/套件推薦 , Python 程式設計 - 高階 by Amo Chen ‐ 4 min read
通常操作 dataframe 完之後,都會需要將結果輸出到資料庫/檔案甚至是雲端服務。 PySpark 已經將相關的輸出都整合到 pyspark.sql.DataFrameWriter 類別,只要理解該類別,基本上就能夠輕鬆將 DataFrame 輸出。
本文將介紹 pyspark.sql.DataFrameWriter 以及幾個使用上值得注意的點。
本文環境
- macOS 13
- Apache Spark 3.2.1
- Docker Desktop 4.4.2
啟動 PySpark Notebook Docker Container 指令
$ docker run -it -p 8888:8888 -v $PWD:/home/jovyan jupyter/pyspark-notebook
DataFrameWriter
PySpark 將所有的輸出功能都整合到 pyspark.sql.DataFrameWriter ,目前該類別支援以下 5 種輸出格式:
稍微簡介一下 Apache 生態系的 3 種資料格式:
- Avro 是有定義結構(schema)而且以二進制儲存的格式
- Parquet 與 ORC 都屬於 Columnar 格式,關於何謂 Columnar 格式,可以參閱這篇文章
如果對 Apache 生態系相關的格式不認識的話,並沒有任何關係,如果暫時沒有儲存容量以及效能的追求,可以使用 CSV 與 JSON 格式即可,好處在於這 2 個格式閱讀與除錯較為方便,如果執行速度與儲存空間的優化已經成為痛點再來考慮使用其他種格式。
輸出範例
以下範例以 4 筆簡單的資料建立 1 個 DataFrame:
from datetime import date
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, IntegerType, DateType
spark = SparkSession.builder.getOrCreate()
schema = StructType([
StructField('id', IntegerType(), False),
StructField('cost', IntegerType(), False),
StructField('createdAt', DateType(), False),
])
spark = SparkSession.builder.getOrCreate()
df = spark.createDataFrame([
{"id": 1, "cost": 100, "createdAt": date(2023, 1, 1)},
{"id": 2, "cost": 200, "createdAt": date(2023, 1, 2)},
{"id": 3, "cost": 250, "createdAt": date(2023, 1, 3)},
{"id": 4, "cost": 250, "createdAt": date(2023, 1, 3)},
], schema=schema)
上述範例執行完成之後,可以呼叫 df.printSchema() 查看資料結構:
df.printSchema()
範例資料的結構如下,可以看到僅有 3 個欄位:
- id
- cost
- createdAt
root
|-- id: integer (nullable = false)
|-- cost: integer (nullable = false)
|-- createdAt: date (nullable = false)
有 dataframe 之後,可以存取其 write 屬性,該屬性就是 DataFrameWriter 的實例(instance):
type(df.write)
# 結果為 pyspark.sql.readwriter.DataFrameWriter
所以要輸出資料只需要呼叫 write 屬性的相關方法即可。
JSON
輸出 JSON, 只要呼叫:
df.write.json('<資料夾路徑>')
輸出路徑只要指定為資料夾路徑即可,檔案名稱的部分 Spark 會自動幫我們決定好。
例如輸出檔案到 ./output/json 資料夾:
df.write.json('./output/json')
輸出成功之後,可以在 jupyter 的 file manager 看到輸出結果,記得先按一下重新整理:
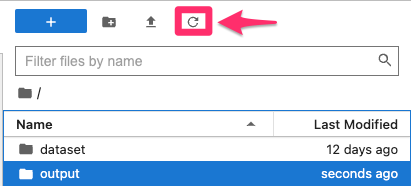
進入該資料夾就會發現多了好幾個檔案:
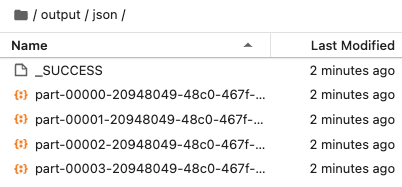
part- 開頭的資料就是被輸出的 DataFrame 資料。
_SUCCESS 檔案代表寫入成功。實務上,如果想自動化檢查檔案是否輸出成功,可以檢查 _SUCCESS 檔案是否存在,如果該檔案不存在,就代表輸出失敗,即使有 part- 開頭的檔案存在也不應該繼續使用。
JSON 格式預設是 JSON lines, 也就是檔案中的每 1 行都是一個完整的 JSON object, 所以如果要用 Jupyter 打開輸出的檔案要選 Editor 才行。
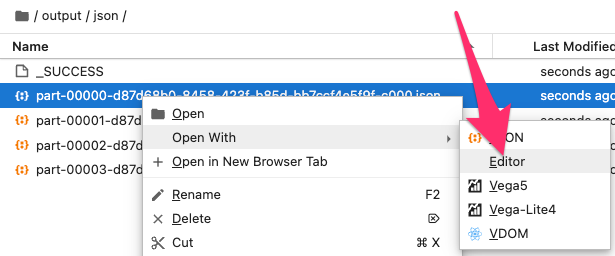
此外,如果重複呼叫 write.json() 或者其他格式的輸出方法,將會出現類似以下的錯誤:
AnalysisException: path file:/home/jovyan/output/json already exists.
其原因在於預設的輸出模式(mode)為 errorifexists , 所以輸出資料夾內有檔案存在時就會拋出錯誤(error), 如果想修正該錯誤,可以帶入 mode='overwrite' 參數:
df.write.json('./output/json', mode='overwrite')
其他格式的使用方法也跟 JSON 的使用方法類似,例如 parquet:
df.write.parquet('./output/parquet', mode='overwrite')
其他格式的方法詳見官方文件。
為什麼 Spark 輸出多個檔案?
有些人可能會好奇為什麼才幾筆資料而已, Spark 卻輸出多個 part-* 檔案,這是由於 Spark 為了能夠平行運算,所以預設會將 dataframe 分成多份,或稱為多個 partition, 所以輸出時也是按照 partition 數輸出,如果想知道 dataframe 有幾個 partition 可以呼叫 rdd 屬性底下的 getNumPartitions() 方法,例如:
df.rdd.getNumPartitions()
本文的 dataframe partitons 為 4, 所以輸出時為 4 個 part-* 檔案:
4
partition()
partition 數量可以呼叫 pyspark.sql.DataFrame.repartition 進行設定,例如將 partition 設定為 3 個:
df = df.repartition(3)
repartition() 方法也可以按照特定欄位,切割 partition, 例如按照 createdAt 欄位切割為 3 份:
df = df.repartition(3, "createdAt")
特定欄位的數量可以是一個以上,例如按照 createdAt 與 cost 切割為 3 份 partition:
df = df.repartition(3, "createdAt", "cost")
切割完可以再呼叫 getNumPartitions() 方法查看數量是否改變:
df.rdd.getNumPartitions()
# 本文結果為 3
試著再次輸出看看:
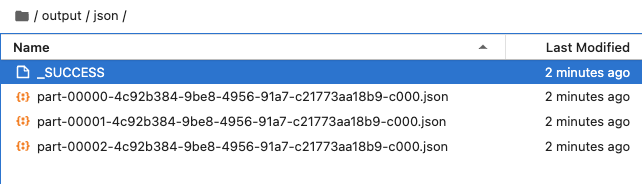
df.write.json('./output/json', mode='overwrite')
從結果可以看到 part-* 檔案已經變成 3 個:
partitionBy()
使用 partition() 方法需要明確指定數量,實務上會使用 DataFrameWriter 的 partitionBy() 方法,指定按照特定欄位切割即可, Spark 會自動將欄位值相同的輸出至同一個 partition, 例如以 createdAt 為 partition 依據:
df.write.partitionBy("createdAt").json('./output/json', mode='overwrite')
p.s. partitionBy() 方法也與 repartition() 相同支援多個欄位的用法
上述輸出結果如下,可以發現輸出資料夾路徑(./output/json)底下多了一層 createdAt=* 的資料夾,標明該資料夾是值為何者的 partition:
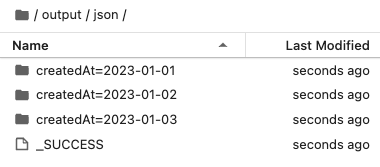
由於有 2 筆資料的 createdAt 值都是 2023-01-03, 所以可以看到 4 筆資料只輸出為 3 個 partition, 其中 createdAt=2023-01-03 會有 2 筆資料:

值得注意的是, createdAt 欄位在輸出結果中消失了,這是由於 Spark 優化輸出,將值寫在資料夾名稱的關係,這種做法在當資料量相當大的情況下,可以節省部分空間。
如果想完整輸出,有個權宜的方法是用 withColumn() 方法複製 1 個欄位專門用來做 partition, 例如:
df.withColumn('_createdAt', df.createdAt)\
.write.partitionBy('_createdAt')\
.json('./output/json', mode='overwrite')
總結
本文透過幾個範例學習如何輸出 Spark 的 DataFrame, 並且從結果進一步認識 partition 對於輸出的影響,實際上 partition 是 Spark 中相當重要的存在,會影響 Spark 的效能,我們之後將針對 partition 進行更深入的介紹。
References
pyspark.sql.DataFrameWriter — PySpark 3.3.1 documentation