零經驗也可的 PySpark 教學 - DataFrame part 2
Posted on Dec 16, 2022 in Python 模組/套件推薦 , Python 程式設計 - 高階 by Amo Chen ‐ 8 min read
繼上一篇 零經驗也可的 PySpark 教學 - DataFrame part 1 之後,本篇將介紹更多關於 DataFrame 的相關操作,包含 JOIN, GROUP BY 等常用的功能。
本文環境
- macOS 13
- Apache Spark 3.2.1
- Docker Desktop 4.4.2
測試資料集
本文使用以下資料集進行操作,請下載該資料並解壓縮該資料集:
https://www.kaggle.com/aashita/nyt-comments
解壓縮完之後,用 cd 指令進入該資料夾:
$ cd nyt-comments/
啟動 PySpark Notebook Docker Container 指令
$ docker run -it -p 8888:8888 -v $PWD:/home/jovyan jupyter/pyspark-notebook
JOIN
RDBMS(Relational Database Management System)提供 SQL JOIN 的功能,讓我們能夠將不同表格資料之間透過關聯(relation)結合起來,同樣地 Spark 也提供 JOIN 的方式將不同的資料結合起來。
常見的 JOIN 方式有以下幾種:
- INNER JOIN
- LEFT JOIN / LEFT OUTER JOIN
- RIGHT JOIN / RIGHT OUTER JOIN
- LEFT ANTI JOIN
- LFET SEMI JOIN
- CROSS JOIN
如果對 JOIN 不熟悉的話,其實可以簡單將 JOIN 理解為數學上的交集(intersect)與聯集(union)等等的概念,如下圖所示:
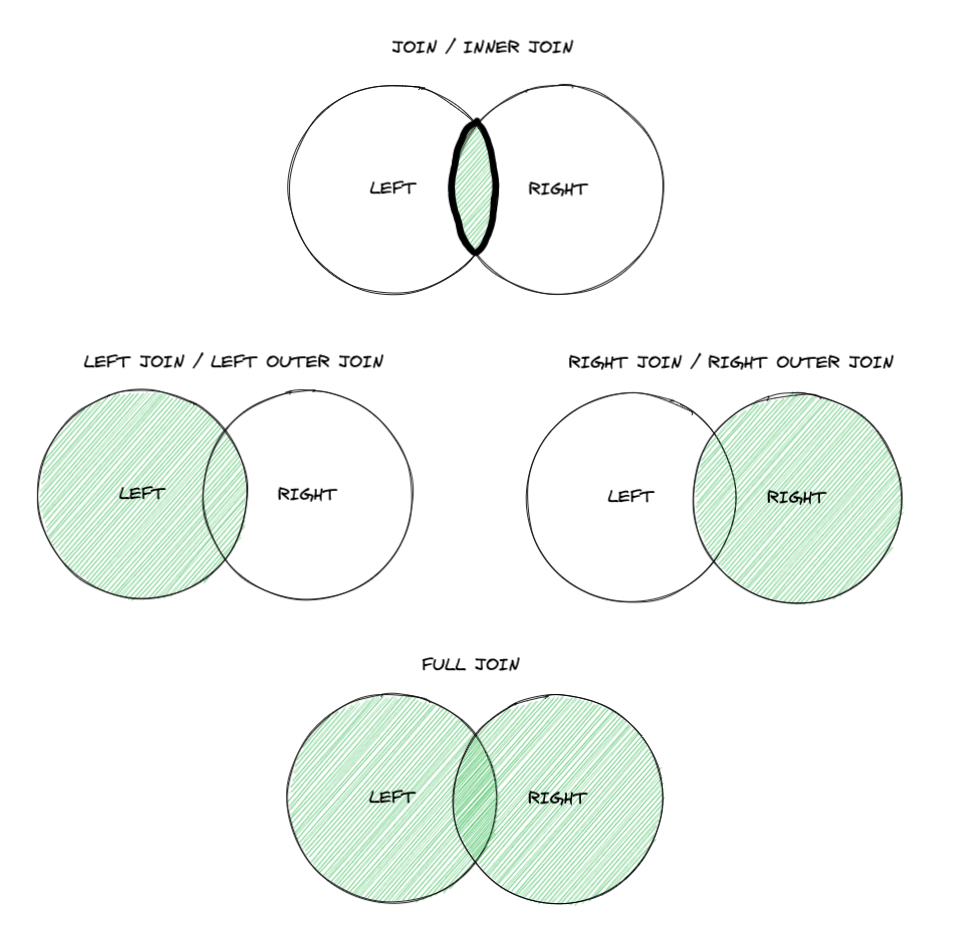
下文將以多個範例進行多種 JOIN 操作。
將 Pandas DataFrame 轉換為 PySpark DataFrame
為了讓 JOIN 的結果更易於確認正確結果,以下本文用 Pandas 製作簡單的 DataFrame 並轉為 PySpark 的 DataFrame 以實際進行 JOIN 運算並查看其結果。
下列範例使用 Pandas 創造 2 個 Pandas DataFrame, 最後呼叫 createDataFrame() 方法將 Pandas DataFrame 轉為 PySpark DataFrame:
import pandas as pd
from pyspark.sql import SparkSession
dataset_1 = [['A', 11], ['B', 22], ['C', 33],['D', 44]]
dataset_2 = [['C', 'type1'], ['D','type2'], ['E', 'type3'],['F','type4']]
pandas_df1 = pd.DataFrame(dataset_1, columns = ['Id', 'Number'])
pandas_df2 = pd.DataFrame(dataset_2, columns = ['Id', 'Type'])
spark = SparkSession.builder.getOrCreate()
df_1 = spark.createDataFrame(pandas_df1)
df_2 = spark.createDataFrame(pandas_df2)
上述 2 個資料其資料如下圖所示,這 2 份資料之間的關聯是 Id 欄位,具有相同 Id 的資料是具有關聯的資料:

做好測試資料之後,接著進行各種 JOIN 的操作。
INNER JOIN
INNER JOIN 只會將有被關聯起來的資料羅列出來。
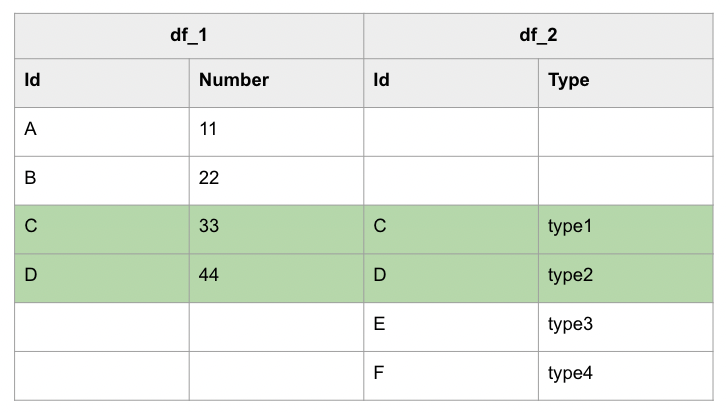
以下是 PySpark 的 INNER JOIN 範例,該範例使用 join() 方法透過 Id 欄位將 df1 與 df2 INNER JOIN 起來,也就是範例中的 df_1.Id == df_2.Id 部分,最後只留取 df1.Id , df2.Number 以及 df2.Type 3 個欄位的資料,也就是 .select(df_1.Id, df_1.Number, df_2.Type) 的部分:
df_1.join(df_2, df_1.Id == df_2.Id, 'inner')\
.select(df_1.Id, df_1.Number, df_2.Type)\
.show()
結果如下所示:
+---+------+-----+
| Id|Number| Type|
+---+------+-----+
| C| 33|type1|
| D| 44|type2|
+---+------+-----+
如果進一步以視覺化進行表示的話,INNER JOIN 其實就是取出下列表格中的綠底部分:
LEFT JOIN / RIGHT JOIN
INNER JOIN 只會將有被關聯起來的資料羅列出來,但如果有些資料不能被關聯起來,但仍要羅列出來的話,就可以使用 LEFT JOIN 或者 RIGHT JOIN 進行操作,而無法被關聯起來的資料欄位就會以 null 代替,光看文字敘述的話仍無法深刻理解何為 LEFT JOIN 或 RIGHT JOIN, 畫成圖之後將會更好理解,如下圖所示:
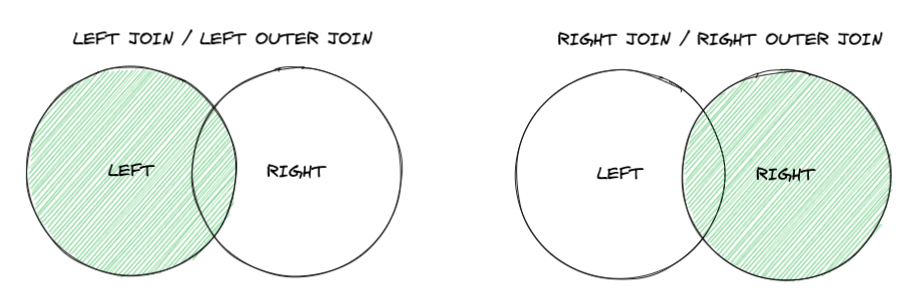
LEFT 與 RIGHT 的差異只在於要以哪一邊的資料為準,也就是上圖中的左邊圈圈或是右邊圈圈。
進一步以視覺化進行表示的話,LEFT JOIN (或 RIGHT JOIN)其實就是取出下列表格中的綠底部分,無法關聯的資料以 null 代替:
LEFT JOIN:
RIGHT JOIN:
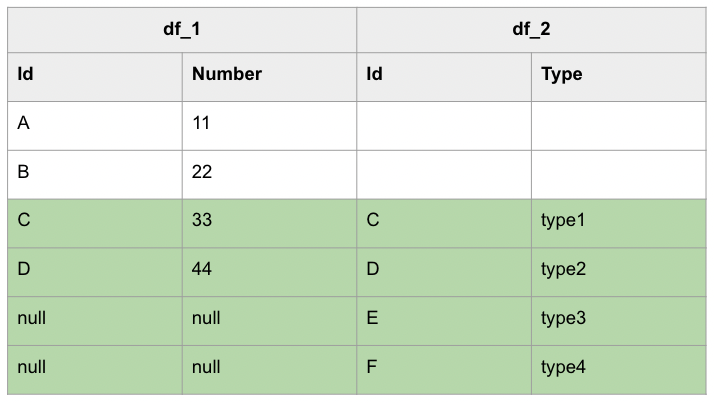
此外, LEFT JOIN 也被稱為 LEFT OUTER JOIN, 兩者之間並無差別,同樣地 RIGHT JOIN 也可被稱為 RIGHT OUTER JOIN。
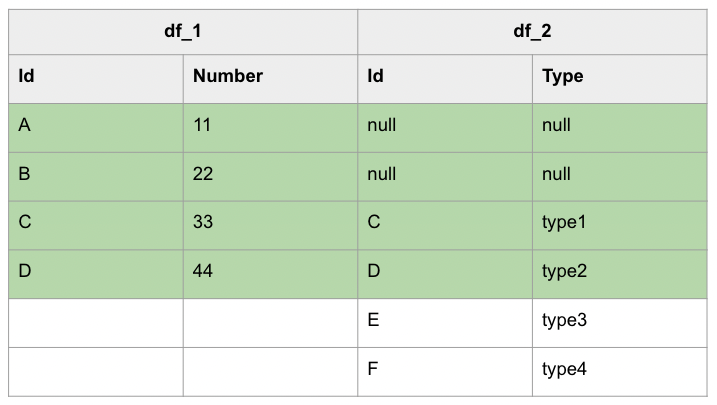
以下是 PySpark LEFT JOIN 的範例,只要將 left 代入 join() 方法的第 3 個參數即可:
df_1.join(df_2, df_1.Id == df_2.Id, 'left')\
.select(df_1.Id, df_1.Number, df_2.Type)\
.show()
上述範例執行結果如下:
+---+------+-----+
| Id|Number| Type|
+---+------+-----+
| A| 11| null|
| B| 22| null|
| C| 33|type1|
| D| 44|type2|
+---+------+-----+
如果想測試 RIGHT JOIN, 可以將參數 left 改為 right :
df_1.join(df_2, df_1.Id == df_2.Id, 'right')\
.select(df_1.Id, df_1.Number, df_2.Type)\
.collect()
上述範例也可以將 df_1 , df_2 對調之後改為 left JOIN, 結果會相同:
df_2.join(df_1, df_2.Id == df_1.Id, 'left')\
.select(df_2.Id, df_1.Number, df_2.Type)\
.collect()
兩者結果都會是:
+----+------+-----+
| Id|Number| Type|
+----+------+-----+
| C| 33|type1|
| D| 44|type2|
|null| null|type3|
|null| null|type4|
+----+------+-----+
OUTER JOIN
OUTER JOIN 也被稱為 FULL JOIN 或 FULL OUTER JOIN, 其 JOIN 結果會無視是否關聯成功,將所有資料都羅列出來,就如同下圖所示:
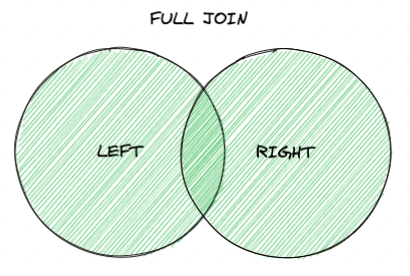
進一步以視覺化進行表示的話,OUTER JOIN 其實就是取出下列表格中的綠底部分:
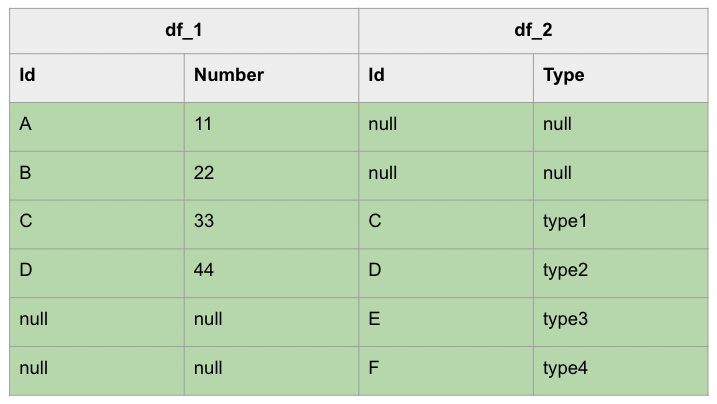
下列是 OUTER JOIN 的範例:
df_1.join(df_2, df_1.Id == df_2.Id, 'full')\
.select(df_1.Id, df_1.Number, df_2.Type)\
.collect()
上述範例執行結果如下:
+----+------+-----+
| Id|Number| Type|
+----+------+-----+
| A| 11| null|
| B| 22| null|
| C| 33|type1|
| D| 44|type2|
|null| null|type3|
|null| null|type4|
+----+------+-----+
LEFT SEMI JOIN
在有些應用場景,我們只希望找到那些存在關聯的資料,而不需要將資料關聯起來,例如寄送行銷郵件時,最基本的策略是寄給有購買紀錄的使用者,而不需要知道使用者購買哪些商品,如果為了達成這項要求,我們可能直覺會想到 INNER JOIN 使用者表格(table)與訂單記錄表格,但是我們又只會用到使用者表格資料中的 email 與姓名資訊,不需要其購買紀錄⋯⋯。
這時就可以使用 LEFT SEMI JOIN:
A semi join returns values from the left side of the relation that has a match with the right. It is also referred to as a left semi join. LEFT SEMI JOIN 與 INNER JOIN 相似,不過 SEMI JOIN 只會保留 LEFT 的資料,例如下圖:
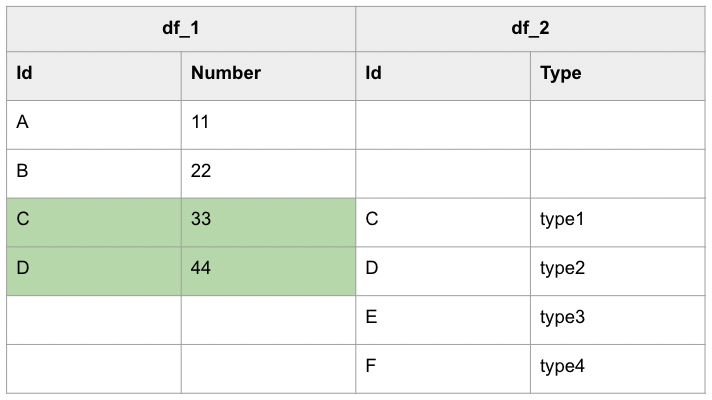
以下是 LEFT SEMI JOIN 的範例:
df_1.join(df_2, df_1.Id == df_2.Id, 'leftsemi')\
.show()
上述範例執行結果如下:
+---+------+
| Id|Number|
+---+------+
| C| 33|
| D| 44|
+---+------+
LEFT ANTI JOIN
與 SEMI JOIN 相反的,就是 ANTI JOIN 。
同樣以寄送行銷郵件為例,為了寄送給沒有消費紀錄的使用者行銷信件,我們就需要檢查每一位使用者是否在訂單表格中有購買紀錄,但最終產出時也不須要購買紀錄的欄位資料(因為不存在),這時候就可以使用 ANTI JOIN 進行操作:
An anti join returns values from the left relation that has no match with the right. It is also referred to as a left anti join.
LEFT ANTI JOIN 會將無法關聯起來的資料羅列出來。
進一步以視覺化進行表示的話,LEFT ANTI JOIN 其實就是取出下列表格中的綠底部分:
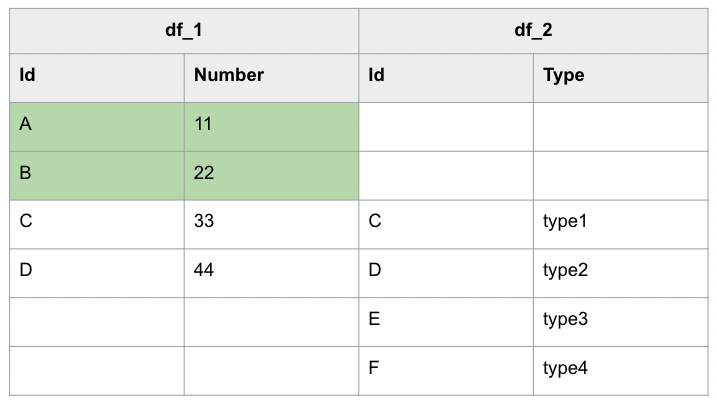
以下為 LEFT ANTI JOIN 的範例:
df_1.join(df_2, df_1.Id == df_2.Id, 'leftanti')\
.show()
上述範例執行結果如下:
+---+------+
| Id|Number|
+---+------+
| A| 11|
| B| 22|
+---+------+
用 SQL 語法進行 JOIN 操作
如果習慣使用 SQL 語法操作 DataFrame 進行 JOIN 的話,也可以呼叫 createOrReplaceTempView() 方法,將 DataFrame 轉為 Local Temporary View ,就能透過 SparkSession 的 sql() 方法 以 SQL 進行操作:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df_1.createOrReplaceTempView('df_1')
df_2.createOrReplaceTempView('df_2')
joined_df = spark.sql('''
select * from df_1
inner join df_2
where df_1.Id == df_2.Id
''')
joined_df.show(truncate=False)
上述範例執行結果如下:
+---+------+---+-----+
|Id |Number|Id |Type |
+---+------+---+-----+
|C |33 |C |type1|
|D |44 |D |type2|
+---+------+---+-----+
詳細的 JOIN SYNTAX 可以參閱 JOIN - Spark 3.3.1 Documentation 文件。
使用真實資料集進行 JOIN
透過簡單的資料體驗過各種 JOIN 操作之後,可以使用真實的資料進行操作看看,實際體驗 Spark 的威力,以下分別載入 NYT 的文章與評論資料到 2 個 DataFrames:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df1 = spark.read\
.option('header', True)\
.option('sep', ',')\
.option('escape', '"')\
.option('inferSchema', True)\
.option('multiline', True)\
.csv('/home/jovyan/CommentsFeb2017.csv')
df2 = spark.read\
.option('header', True)\
.option('sep', ',')\
.option('escape', '"')\
.option('inferSchema', True)\
.option('multiline', True)\
.csv('/home/jovyan/ArticlesFeb2017.csv')
有了真實資料之後,就能夠實際進行 JOIN 操作看看,例如以下 3 個範例,分別是 INNER JOIN, LEFT JOIN 與 RIGHT JOIN 。
INNER JOIN 範例:
df1.filter(df1.userID == '67892453')\
.join(df2, df1.articleID == df2.articleID, 'inner')\
.select(df1.userID, df2.articleID, df2.headline).\
collect()
LEFT JOIN 範例:
df1.filter(df1.userID == '67892453')\
.join(df2, df1.articleID == df2.articleID, 'left')\
.select(df1.userID, df2.articleID, df2.headline)\
.collect()
RIGHT JOIN 範例:
df1.filter(df1.userID == '67892453')\
.join(df2, df1.articleID == df2.articleID, 'right')\
.select(df1.userID, df2.articleID, df2.headline)\
.collect()
Alias 別名
PySpark 的欄位(column)提供 alias() 方法,讓我們能夠在查詢時,給欄位指定個別名(alias)以方便我們賦予欄位更清楚的名字或者方便我們後續用別名操作欄位,譬如下列範例將 replyCount 指定別名為 reply_count :
df1.select(
df1.replyCount.alias('reply_count')
).show(1)
上述範例執行結果如下,可以看到欄位 replyCount 的名稱已經換成 reply_count :
+-----------+
|reply_count|
+-----------+
| 0|
+-----------+
前述範例,以 SQL 進行表示的話:
df1.createTempView('df1')
spark.sql('''
select
replyCount as reply_count
from
df1
''').show(1)
除了直接指定別名給欄位之外,也可以對欄位進行運算後,再指定新的別名:
df1.select(
(df1.replyCount + 1000).alias('reply_count_k')
).show(1)
上述範例執行結果如下:
+-------------+
|reply_count_k|
+-------------+
| 1000|
+-------------+
前述範例,以 SQL 進行表示的話:
spark.sql('''
select
(replyCount + 1000) as reply_count
from
df1
''').show(1)
GROUP BY
GROUP BY 也是經常使用的 SQL 操作之一。
例如針對將某些資料分為群組之後取得最大值(max)、最小值(min)、加總(sum)或計算平均值(avg)等,就能夠使用 GROUP BY 的功能。
PySpark 的 DataFrame 也提供 groupBy() 方法,讓我們進行前述的操作,例如下列範例,我們想知道每個 New York Times comment 資料集的 commentType 與其相對應的資料筆數,可以使用 groupBy 搭配 count 進行:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read\
.option('header', True)\
.option('sep', ',')\
.option('escape', '"')\
.option('inferSchema', True)\
.option('multiline', True)\
.csv('/home/jovyan/CommentsFeb2017.csv')
df.groupBy([df.commentType]).count().show()
上述範例執行結果如下:
+-------------+------+
| commentType| count|
+-------------+------+
| userReply| 51642|
| comment|181750|
|reporterReply| 15|
+-------------+------+
上述結果可以看到資料並沒有按照按照 count 欄位排序,如果需要遞減排序,可以呼叫 orderBy() 方法搭配 pyspark.sql.functions.desc :
from pyspark.sql.functions import desc
df.groupBy([
df.commentType
]).count().orderBy(desc('count')).show()
p.s. orderBy 方法是 sort() 的別名(alias),兩者是相同的方法
上述範例執行結果如下:
+-------------+------+
| commentType| count|
+-------------+------+
| comment|181750|
| userReply| 51642|
|reporterReply| 15|
+-------------+------+
遞增排序可以使用 pyspark.sql.functions.asc:
from pyspark.sql.functions import asc
df.groupBy([
df.commentType
]).count().orderBy(asc('count')).show()
+-------------+------+
| commentType| count|
+-------------+------+
|reporterReply| 15|
| userReply| 51642|
| comment|181750|
+-------------+------+
結合 groupBy() 與 agg() 進行聚合運算
groupBy() 方法經常會與 agg() 一起使用, agg() 方法提供我們與 SQL aggregate function(或稱聚合函數)相同作用的功能,可以針對每個 group 取出各自的最大值、最小值、總和等等的運算,也是在查詢資料時很常用到的功能。
例如以下範例以 articleID 作為分組(group)依據,接著呼叫 agg() 方法,找出該組最早與最晚的 comment 建立時間,並兩者相減後轉為天數當作 article 的壽命,也就是 duriationInDays ,最後按照 duriationInDays 遞減排序,即可找到壽命最長的文章:
from pyspark.sql import functions as f
maxCreateTime = f.max(df.createDate).alias('maxCreateTime')
minCreateTime = f.min(df.createDate).alias('minCreateTime')
durationInDays = ((maxCreateTime - minCreateTime) / 86400).alias('durationInDays')
df.groupBy(df.articleID).agg(
durationInDays,
).orderBy(
f.desc('durationInDays')
).show(1, truncate=False)
上述範例執行結果如下,可以看到壽命最長的文章長達 416 天:
+------------------------+-----------------+
|articleID |durationInDays |
+------------------------+-----------------+
|58936eda95d0e0392607e41a|416.1987731481481|
+------------------------+-----------------+
如果化為 SQL 形式,等同下列範例:
df.createTempView('df')
spark.sql('''
select
((max(df.createDate) - min(df.createDate)) / 86400) as durationInDays
from
df
group by
df.articleID
order by
durationInDays desc
limit 1
''').show(truncate=False)
p.s. 如果想了解 PySpark 提供哪些函式可供使用,可以參閱 Spark SQL — Functions 章節。
當然, groupBy() 方法也支援多個欄位的 group by, 下列範例以 userLocation 與 commentType 2 個欄位作為分組依據,並計算文章 Id 為 58936eda95d0e0392607e41a 的各個群組的 count:
df.filter(df.articleID == '58936eda95d0e0392607e41a')\
.groupBy(df.userLocation, df.commentType)\
.count()\
.orderBy(f.desc('count'))\
.show()
上述範例執行結果如下,可以看到文章 Id 為 58936eda95d0e0392607e41a 的 comment 資料中以來自 New York, NY 與 commentType 為 userReply 的資料 8 筆最多:
+-------------+-----------+-----+
| userLocation|commentType|count|
+-------------+-----------+-----+
| New York, NY| userReply| 8|
| New York| comment| 7|
|New York City| userReply| 6|
| Sweden| userReply| 4|
| New York| userReply| 3|
|New York City| comment| 3|
| Florida| comment| 3|
| NY| userReply| 3|
| New York, NY| comment| 3|
| NYC| comment| 3|
| Sweden| comment| 3|
| New Jersey| userReply| 3|
| NYC| userReply| 3|
| NYV| comment| 2|
| Michigan| comment| 2|
| Cincinnati| comment| 2|
| Los Angeles| comment| 2|
| California| comment| 2|
| Chicago| comment| 2|
| Berkeley, CA| userReply| 2|
+-------------+-----------+-----+
以 UNION 合併 DataFrame
當有多個 DataFrame 具有相同欄位時,可以呼叫 unionByName() 進行合併(或稱為 concatenate):
import pandas as pd
from pyspark.sql import SparkSession
dataset_1 = [['A', 11], ['B', 22], ['C', 33],['D', 44]]
dataset_2 = [['E', 44],['F', 55]]
pandas_df1 = pd.DataFrame(dataset_1, columns = ['Id', 'Number'])
pandas_df2 = pd.DataFrame(dataset_2, columns = ['Id', 'Number'])
spark = SparkSession.builder.getOrCreate()
df_1 = spark.createDataFrame(pandas_df1)
df_2 = spark.createDataFrame(pandas_df2)
df_3 = df_1.unionByName(df_2)
df_3.show()
上述範例執行結果如下,可以看到 2 個 DataFrame 被合併:
+---+------+
| Id|Number|
+---+------+
| A| 11|
| B| 22|
| C| 33|
| D| 44|
| E| 44|
| F| 55|
+---+------+
由於 DataFrame 每個欄位具有型別,所以 PySpark 如果遇到資料欄位的型別不一致的情況會嘗試幫忙處理型別轉換的問題,但如果遇到無法處理的情況就會出現類似以下的錯誤訊息,這時侯就需要檢查欄位的資料型別是否一致,並轉換成適合的型別後,再行合併:
AnalysisException Traceback (most recent call last)
...
AnalysisException: Union can only be performed on tables with the compatible column types. The 11th column of the second table is boolean type which is not compatible with int at same column of first table;
'Union false, false
總結
以上為如何用 PySpark 進行 GROUP BY, AGGREGATION 以及 UNION 的教學。
如果只是想試試 DataFrame 的各種功能,也不妨可以試試 Binder 服務,該服務也提供 Jupyter Notebook 以及 PySpark 的環境可以做些簡單的實驗。
References
RDD Programming Guide - Spark 3.3.1 Documentation
RDD, Datarame and Datasets in Apache Spark