零經驗也可的 PySpark 教學 - DataFrame part 1
Last updated on Dec 16, 2022 in Python 模組/套件推薦 , Python 程式設計 - 高階 by Amo Chen ‐ 6 min read
上一篇 零經驗也可的 PySpark 教學 - 初體驗 ,我們透過 Docker 輕易地體驗到 PySpark 的功能,利用 PySpark 將 CSV 資料載入 DataFrame ,再將 DataFrame 轉成 temporary view 後,我們就能夠使用 SQL 對資料進行操作,過程相當輕鬆寫意。
不過 DataFrame 提供相當多的 API, 讓開發者能夠像操作 ORM(Object Relational Mapping) 一樣進行開發,可說是 PySpark 學習過程必須學會的一環,本篇將介紹更多關於 DataFrame 的相關操作,包含 SELECT, FILTER, JOIN, UNION 等常用的功能。
本文環境
- macOS 13
- Apache Spark 3.2.1
- Docker Desktop 4.4.2
測試資料集
本文使用以下資料集進行操作,請下載該資料並解壓縮該資料集:
https://www.kaggle.com/aashita/nyt-comments
解壓縮完之後,用 cd 指令進入該資料夾:
$ cd nyt-comments/
啟動 Pyspark Notebook Docker Container 指令
$ docker run -it -p 8888:8888 -v $PWD:/home/jovyan jupyter/pyspark-notebook
轉換欄位資料型態
上一篇教學 介紹載入資料時使用 option('inferSchema', True) 讓 Spark 自動推論每個欄位的資料型態,例如:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read\
.option('header', True)\
.option('sep', ',')\
.option('escape', '"')\
.option('inferSchema', True)\
.option('multiline', True)\
.csv('/home/jovyan/CommentsFeb2017.csv')
自動推論資料型態的功能十分方便,可以節省為每個欄位設定資料型態的時間。
不過,自動推論也有失準的時候,這時可以使用 pyspark.sql.DataFrame.withColumn 與 pyspark.sql.functions.col 將錯誤的資料型態轉為正確的資料型態,例如以下示範將 replyCount 從 int 轉為 long:
from pyspark.sql.functions import col
df = df.withColumn(
'replyCount',
col('replyCount').cast('long'),
)
成功之後可以查看 df 的 schema:
df.printSchema()
上述執行結果如下,可以看到 replyCount 已經被轉為 long 型態:
root
...(略)...
|-- replyCount: long (nullable = true)
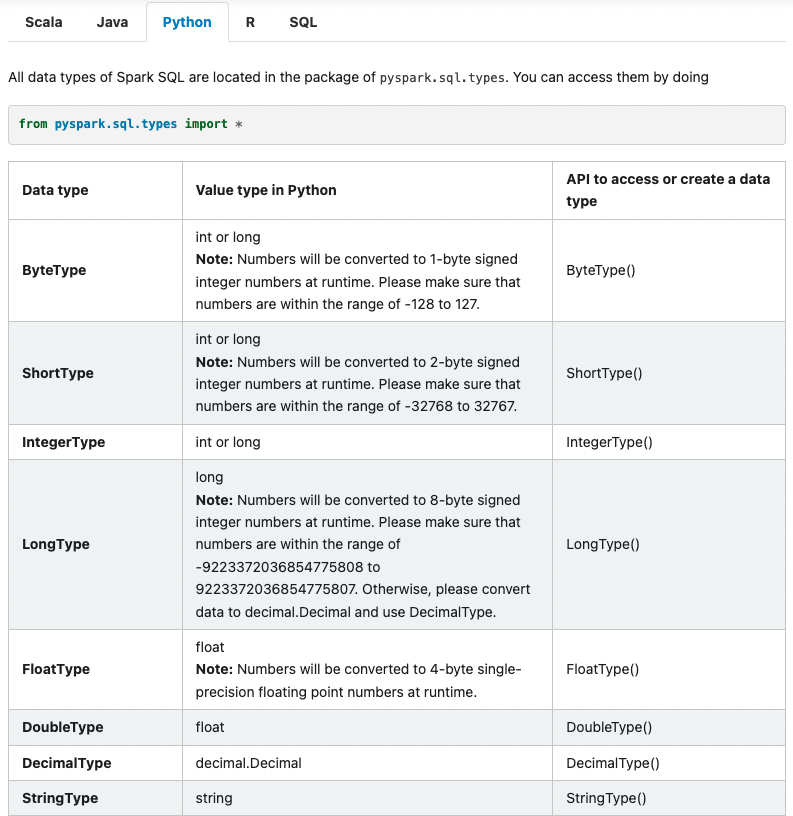
Spark 對應到 Python 資料型態的表格可以參閱 Data Types 一文:
何謂 DataFrame?
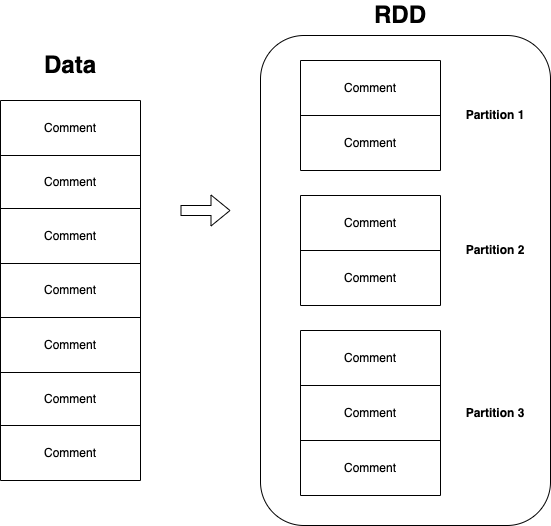
在詳細介紹 DataFrame 之前,必須認識何謂 RDD(Resilient Distributed Dataset)。
RDD 是 Spark 1.0 就存在的最基本的抽象化概念,代表被切割成多塊(partitioned)且可供平行(parallel)運算的不可更動(immutable)資料,如果以圖表示的話,如下圖:
而所謂的平行指的是可以將不同的 partitions 分配到 Spark 叢集(cluster)中的運算節點中進行運算,如果以圖表示的話,如下圖:
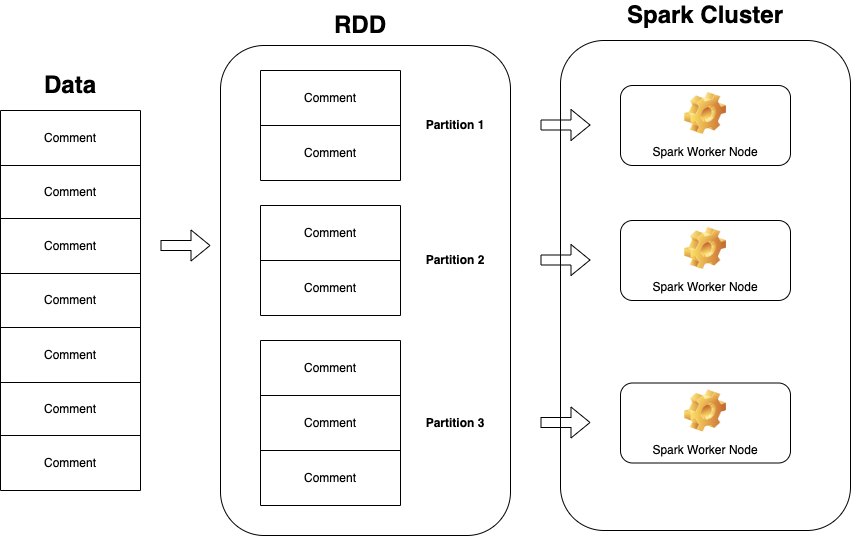
p.s. 當然不一定每個 node 都恰好會分到相同數量的 partition
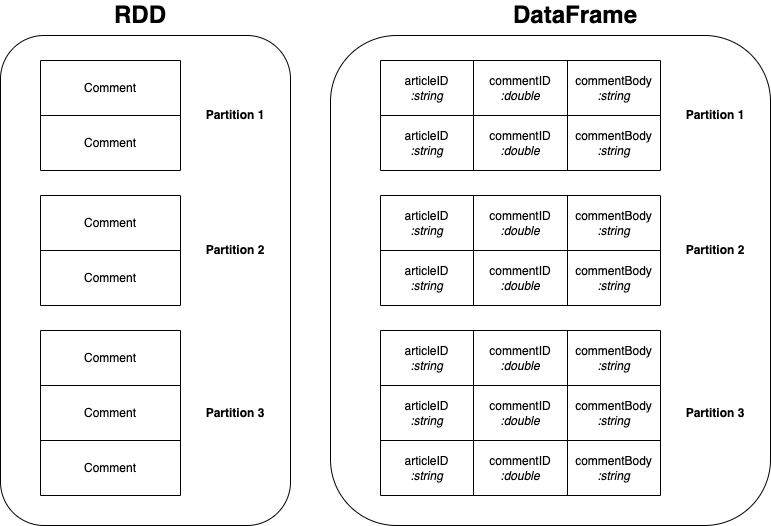
後來到了 Spark 1.3, 官方基於 RDD, 推出 DataFrame 作為另一種抽象化概念,可以視為跟關聯式資料庫中的資料表(table)是相同的概念,讓我們操作上更加直觀:
A DataFrame is a Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood.
DataFrame 與 RDD 類似,同樣具有被切割成多塊(partitioned),可供平行(parallel)運算且不可更動(immutable)的特性。
RDD 與 DataFrame 最大不同在於:
- RDD 沒有資料型態、DataFrame 有資料型態
- RDD 是以 Row 為單位的集合,而 DataFrame 同樣是以 Row 為單位的集合,但是多了欄位(column)的概念,呼應第 1 點提到的資料型態之外,也是為了讓 DataFrame 就像關聯式資料庫的資料表一樣
- DataFrame 相對 RDD 而言做了許多效率優化
Spark 1.3 之後,大多推薦使用 DataFrame 進行操作,除了效率較好之外, DataFrame 所提供的 APIs 也相對方便使用,不過有些文件 Spark 仍會提到 RDD, 因此理解 RDD 與 DataFrame 的不同之後,如果翻閱 Spark 文件有提到 RDD 的話,就能夠比較理解文件想表達的意思。
當我們呼叫 spark.read.csv() 載入 CSV 資料時,會得到一個 DataFrame, 我們可以用 type() 函式檢查其型別:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read\
.option('header', True)\
.option('sep', ',')\
.option('escape', '"')\
.option('inferSchema', True)\
.option('multiline', True)\
.csv('/home/jovyan/CommentsFeb2017.csv')
type(df) # 其結果為 pyspark.sql.dataframe.DataFrame
DataFrame 的文件註解有許多方法的解釋與範例,可以使用 help() 方法查看:
help(df)
上述範例執行結果如下:
Help on DataFrame in module pyspark.sql.dataframe object:
class DataFrame(pyspark.sql.pandas.map_ops.PandasMapOpsMixin, pyspark.sql.pandas.conversion.PandasConversionMixin)
| DataFrame(jdf: py4j.java_gateway.JavaObject, sql_ctx: Union[ForwardRef('SQLContext'), ForwardRef('SparkSession')])
|
| A distributed collection of data grouped into named columns.
|
| A :class:`DataFrame` is equivalent to a relational table in Spark SQL,
| and can be created using various functions in :class:`SparkSession`::
|
| people = spark.read.parquet("...")
|
| Once created, it can be manipulated using the various domain-specific-language
| (DSL) functions defined in: :class:`DataFrame`, :class:`Column`.
|
| To select a column from the :class:`DataFrame`, use the apply method::
|
| ageCol = people.age
|
| A more concrete example::
|
| # To create DataFrame using SparkSession
| people = spark.read.parquet("...")
| department = spark.read.parquet("...")
|
| people.filter(people.age > 30).join(department, people.deptId == department.id) \
| .groupBy(department.name, "gender").agg({"salary": "avg", "age": "max"})
...(略)...
如果想學習 PySpark DataFrame 如何使用,可以詳閱上述 help 文件。
查看欄位與資料型態 - printSchema()
認識 DataFrame 之後,可以從查看 DataFrame 的欄位與資料型態開始。
如果想查看 DataFrame 的資料型態,可以呼叫 printSchema() 方法:
df.printSchema()
上述範例執行結果如下:
root
|-- approveDate: integer (nullable = true)
|-- articleID: string (nullable = true)
|-- articleWordCount: integer (nullable = true)
|-- commentBody: string (nullable = true)
|-- commentID: double (nullable = true)
|-- commentSequence: double (nullable = true)
|-- commentTitle: string (nullable = true)
|-- commentType: string (nullable = true)
|-- createDate: integer (nullable = true)
|-- depth: double (nullable = true)
|-- editorsSelection: integer (nullable = true)
|-- inReplyTo: integer (nullable = true)
|-- newDesk: string (nullable = true)
|-- parentID: double (nullable = true)
|-- parentUserDisplayName: string (nullable = true)
|-- permID: string (nullable = true)
|-- picURL: string (nullable = true)
|-- printPage: integer (nullable = true)
|-- recommendations: integer (nullable = true)
|-- recommendedFlag: string (nullable = true)
|-- replyCount: integer (nullable = true)
|-- reportAbuseFlag: string (nullable = true)
|-- sectionName: string (nullable = true)
|-- sharing: integer (nullable = true)
|-- status: string (nullable = true)
|-- timespeople: integer (nullable = true)
|-- trusted: integer (nullable = true)
|-- updateDate: integer (nullable = true)
|-- userDisplayName: string (nullable = true)
|-- userID: double (nullable = true)
|-- userLocation: string (nullable = true)
|-- userTitle: string (nullable = true)
|-- userURL: string (nullable = true)
|-- typeOfMaterial: string (nullable = true)
存取 DataFrame 欄位
存取 DataFrame 欄位有 2 種方式,第 1 種是當作 property ㄧ樣用 . 進行存取,例如 df.replyCount ,第 2 種是當作 dictionary 一樣存取,例如 df['replyCount'] 。
df.replyCount
# 等於
df['replyCount']
這 2 種存取方式都會回傳 Column instance, 不過與 Pandas 不同, Pandas 的 DataFrame 存取欄位時會回傳所有該欄位的資料,而 PySpark 回傳的僅是代表一個欄位(column)的 instance, 可以想像成 ORM 中的欄位屬性,該 instance 可以做為 pyspark.sql.DataFrame.withColumn 或 pyspark.sql.DataFrame.select 等方法的參數。
查看 DataFrame 資料筆數
如果想知道 DataFrame 有多少筆資料,可以呼叫 count() 方法:
df.count()
上述範例執行結果如下:
233442
查看特定欄位統計資訊
如果想查看特定欄位的統計資訊,例如平均值、標準差、最大最小值,可以呼叫 describe() 方法:
df.describe(['replyCount']).show()
上述範例執行結果如下:
+-------+-------------------+
|summary| replyCount|
+-------+-------------------+
| count| 233407|
| mean|0.49543929702194023|
| stddev| 2.6125512279272165|
| min| 0|
| max| 335|
+-------+-------------------+
如果想一次顯示多個欄位的統計資訊,可以代入多個欄位:
df.describe(['replyCount', 'sharing']).show()
上述範例執行結果如下:
+-------+-------------------+-------------------+
|summary| replyCount| sharing|
+-------+-------------------+-------------------+
| count| 233407| 233407|
| mean|0.49543929702194023|0.08872912980330495|
| stddev| 2.6125512279272165| 0.2843529808998737|
| min| 0| 0|
| max| 335| 1|
+-------+-------------------+-------------------+
刪除欄位
如果想刪除特定欄位,可以呼叫 pyspark.sql.DataFrame.drop 方法, 例如以下刪除 userID 欄位:
df = df.drop(df.userID)
如要一次刪除多個欄位,可以代入多個欄位:
df = df.drop(df.userID, df.sharing)
p.s. 此方法會回傳新的 DataFrame
重新命名欄位
pyspark.sql.DataFrame.withColumnRenamed 方法則可以用來重新命名欄位,例如以下將 age 改名為 age2:
df = df.withColumnRenamed('age', 'age2')
p.s. 此方法會回傳新的 DataFrame
取代/修改欄位資料
有時候,會需要對 DataFrame 的既有欄位做些運算,例如將數值統一除以 1000 轉換單位,或轉換時間格式等等,這時可以使用 withColumn() 方法:
df = df.withColumn('replyCount', f.col('replyCount') / 1000)
p.s. 此方法會回傳新的 DataFrame
新增欄位
withColumn() 方法也同樣可以用在新增欄位:
df = df.withColumn('newReplyCount', f.col('replyCount') / 1000)
SELECT
pyspark.sql.DataFrame.select 方法可以執行與 SQL SELECT 等效的 query:
df.select(df.userDisplayName, df.userLocation).show(5)
上述範例執行結果如下:
+---------------+------------+
|userDisplayName|userLocation|
+---------------+------------+
| vilonia| conway, ar|
| Joe Schultz| Hays, KS|
| WilliamPenn2| Tacony|
| Jeff Palmer| Shiloh, IL|
| Matt1234| Seattle|
+---------------+------------+
也可以搭配 pyspark.sql.DataFrame.limit 限制筆數:
df.select(df.userDisplayName, df.userLocation).limit(5)
p.s. select 與 limit 方法會回傳新的 DataFrame
p.s. show 方法只是用來列印結果,並不會回傳新的 DataFrame, 所以別將 show 與 limit 的用途搞混
WHERE
有 SELECT 就會有 WEHRE 的使用需求。
pyspark.sql.DataFrame.where 方法提供篩選資料的功能,該方法等同於 pyspark.sql.DataFrame.filter 方法,例如下列範例篩選 replyCount 的 5 筆資料:
df.where(df.replyCount == 0).limit(5).collect()
# 等同於
df.filter(df.replyCount == 0).limit(5).collect()
如果需要多個過濾條件可以 & AND 或 | OR 將條件串聯:
& AND 條件範例:
df.where(
(df.userLocation == 'Seattle') & (df.replyCount == 0)
).limit(5).show()
| OR 條件範例:
df.where(
(df.userLocation == 'Seattle') | (df.userLocation == 'Tacony')
).limit(5).show()
記得每個條件都需要用括號 ( ) 包起來,否則就會出現類似以下的錯誤:
Py4JError: An error occurred while calling o266.or. Trace:
py4j.Py4JException: Method or([class java.lang.String]) does not exist
at py4j.reflection.ReflectionEngine.getMethod(ReflectionEngine.java:318)
at py4j.reflection.ReflectionEngine.getMethod(ReflectionEngine.java:326)
at py4j.Gateway.invoke(Gateway.java:274)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.base/java.lang.Thread.run(Thread.java:833)
pyspark.sql.DataFrame.where 方法也能接受代入 string 類型的參數,例如前述範例可以改為下列形式:
df.where(
"userLocation == 'Seattle' OR userLocation == 'Tacony'"
).limit(5).show()
查看符合特定條件的資料筆數
pyspark.sql.DataFrame.where 方法也能結合 pyspark.sql.DataFrame.count 方法算出符合特定條件的資料筆數,例如下列計算 replyCount 為 0 的資料筆數:
df.where(df.replyCount == 0).count()
總結
為避免文章篇幅過長,本文將分為 2 篇進行。
下一篇將介紹如何進行 JOIN 多個 DataFrame, 對 DataFrame 進行聚合(aggregation)查詢等等。
以上, Happy Coding!
References
RDD Programming Guide - Spark 3.3.1 Documentation
RDD, Datarame and Datasets in Apache Spark