零經驗也可的 PySpark 教學 - 初體驗
Last updated on Dec 16, 2022 in Python 模組/套件推薦 , Python 程式設計 - 高階 by Amo Chen ‐ 5 min read
Apache Spark 是現今處理巨量資料(large-scale data)分析、資料處理、機器學習(machine learning)的主流叢集運算框架之一,其主打簡單、快速、可擴充(scalable)、統一介面(unified) 4 大特點,更支援多種語言(Python, Java, R, SQL)可供靈活選擇運用。
Spark 採用的是 In-memory 運算技術,運算的資料存在於記憶體之中,相對於使用硬碟等儲存媒介的運算框架(例如 Apache Hadoop)而言, Spark 具有運算速度的優勢。
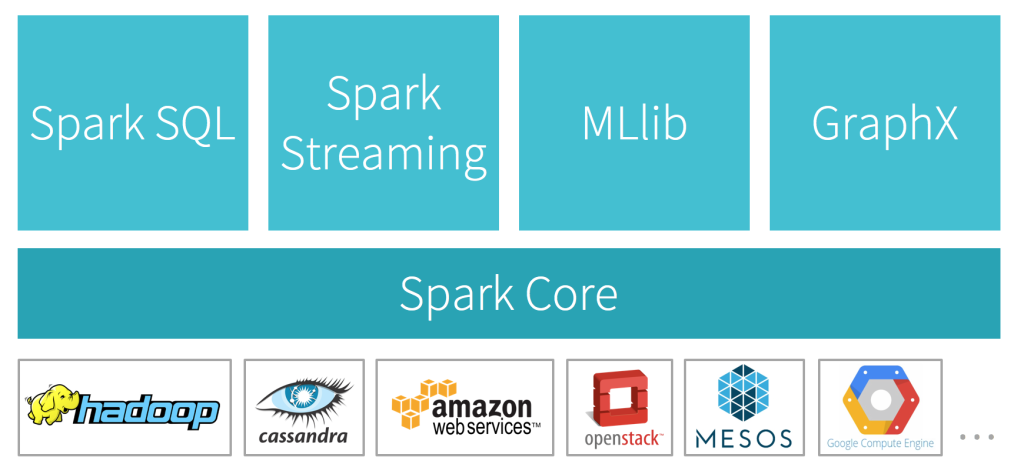
此外,除了提供核心運算功能的 Spark Core, Apache Spark 更在其基礎上衍生 Spark SQL, Spark Streaming, MLlib, GraphX 四大功能:
- Spark SQL - 支援以 SQL 對資料進行操作、運算
- Spark Streaming - 讓 Spark 能夠處理串流(streaming)形式的資料
- MLlib - 增加機器學習(machine learning)的相關函式庫(library),讓開發者得以利用 Apache Spark 進行機器學習相關的運算
- GraphX - 支援圖論(graph theory)相關的運算,像社群網絡(social network)相關數據分析就適合使用 GraphX 進行運算
 引用自 https://databricks.com
引用自 https://databricks.com
綜觀來說,Apache Spark 是相當值得投資學習的一套運算框架。
本文將透過 Docker 以及 PySpark 為初學者提供接觸 Apache Spark 的一條捷徑。
本文環境
- macOS 11.6
- Apache Spark 3.2.1
- Docker Desktop 4.4.2
PySpark
PySpark 是以 Python 開發的 Apache Spark 介面(interface),讓我們可以用 Python 輕鬆地開發 Spark 相關的應用(application)或運算(computation)。
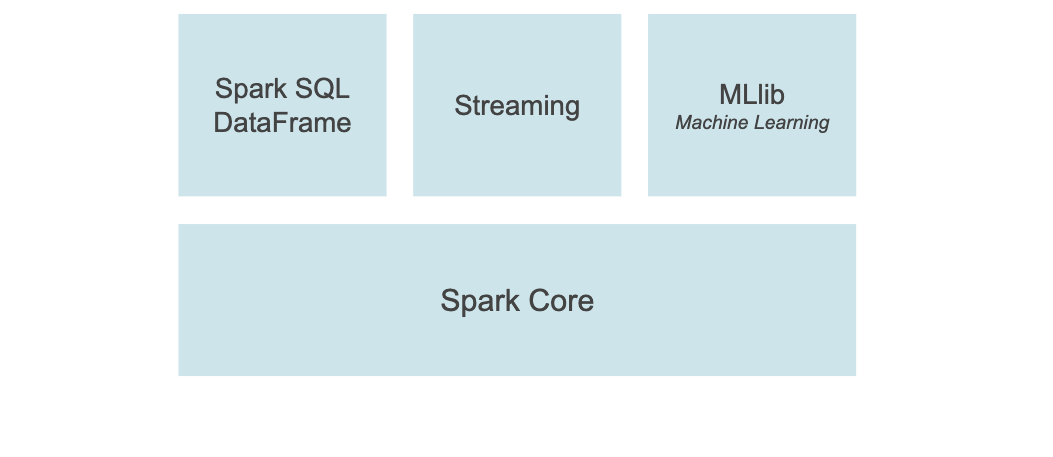
PySpark 也支援 Spark SQL, Streaming, MLlib, Spark Core 功能。
 引用自 https://spark.apache.org
引用自 https://spark.apache.org
另外,如果熟悉 pandas 的話,也可以很輕鬆上手 PySpark , 因為 PySpark 的 API 與 pandas 的 API 十分相似,加上兩者整合度很好,所以可以輕鬆地在兩者間進行切換。
測試資料集
本文使用以下資料集進行操作,請下載該資料並解壓縮該資料集:
https://www.kaggle.com/aashita/nyt-comments
解壓縮完之後,用 cd 指令進入該資料夾:
$ cd nyt-comments/
Jupyter Docker Stacks - pyspark-notebook
受益於容器化(containerization)技術的誕生,學習新技能之前的環境架設門檻已經被大幅降低,我們可以輕易地透過官方或社群(community)所提供的 Docker 映像檔(image)進行體驗與踏上學習之旅。
如果想透過 PySpark 學習使用 Apache Spark 的話,可以使用 Jupyter Docker Stacks 提供的 pyspark-notebook Docker 映像檔(image),可以節省環境架設的時間成本(如果想了解如何架設就可以參考其 Dockerfile)。
啟動 pyspark-notebook 的指令如下:
$ docker run -it -p 8888:8888 -v $PWD:/home/jovyan jupyter/pyspark-notebook
上述指令 -p 8888:8888 代表將送往 localhost:8888 的通訊轉送至 Docker container 的 8888 通訊埠,也就是 Jupyter notebook 所使用的通訊埠;而 -v $PWD:/home/jovyan 代表將當前資料夾掛載(mount)至 Docker container 內的路徑 /home/jovyan 。
執行成功的話,可以看到 Jupyter notebook 的連結:

以瀏覽器打開上述連結,可以看到以下畫面:
這樣就完成 Apache Spark 與 PySpark 的環境架設囉!
順帶一提, jovyan 是 Jupyter Docker Stacks 相關映像檔的預設使用者帳號,如果想要換成自己習慣的帳號,可以有以下 2 種方式達成,建議使用第 2 種:
- pull 其 git repository 重新編譯(build)映像檔
- 執行 docker run 時加上
--user root -e NB_USER=<使用者帳號> -e CHOWN_HOME=yes -w "/home/${NB_USER}",例如:
$ docker run -it --rm \
-p 8888:8888 \
--user root \
-e NB_USER="my-username" \
-e CHOWN_HOME=yes \
-w "/home/${NB_USER}" \
jupyter/pyspark-notebook
p.s. 上述方式會新增一個新的使用者帳號,所以 jovyan 依然會存在
接著新增一個 Jupyter notebook 的頁面後,就來一步一步稍微體驗一下 Spark 吧!
以下章節的範例程式碼請在 Jupyter notebook 中輸入執行
Session
欲操作 Spark 的一切功能,首先必須使用 SparkSession 建立 1 個 session.
The entry point into all functionality in Spark is the SparkSession class.
建立 Session 的程式碼如下:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
讀取資料
建立 Spark session 之後,就能夠試著讀取資料,將資料載入至記憶體中以便後續進行運算。
Spark 支援多種資料格式,包含 CSV, JSON, Parquet, 純文字(Text) 等常見的格式,本文範例讀取 CSV 格式的檔案:
df = spark.read\
.option('header', True)\
.option('escape', '"')\
.csv('/home/jovyan/CommentsFeb2017.csv')
上述範例的 .option('header', True) 代表將 CSV 檔案的第 1 行視為欄位名稱;而 .option('escape', '"') 則是設定 CSV 欄位值如果含有 " 雙引號時要如何逸出(escape), 例如欄位值為 我是一名"程式"設計師 的話,經過 " 逸出之後就會變成 我是""程式""設計師 。
資料載入成功之後,會回傳 1 個 DataFrame 的實例(instance),DataFrame 等同關聯式資料庫(RDBMS)中的表格(table),所以 DataFrame 也提供像 SQL 一樣的介面可供查詢/運算資料,我們將在後續章節進行相關操作。
載入資料之後可以呼叫 printSchema() 查看資料的結構:
df.printSchema()
執行結果如下,從結果可以看到所有欄位都是字串型態 string (nullable = true) , 這是由於 Spark 預設不會為 CSV 格式的資料設定型態(type)。
root
|-- approveDate: string (nullable = true)
|-- articleID: string (nullable = true)
|-- articleWordCount: string (nullable = true)
...(略)...
|-- userTitle: string (nullable = true)
|-- userURL: string (nullable = true)
|-- typeOfMaterial: string (nullable = true)
資料型態的不同,有時會導致運算結果無法如我們預期般呈現,所以我們可以透過增加 .option("inferSchema", True) ,讓 Spark 為每個欄位的資料自動推論(infer)其型態:
df = spark.read\
.option('header', True)\
.option('escape', '"')\
.option('inferSchema', True)\
.csv('/home/jovyan/CommentsFeb2017.csv')
再次查看資料結構(schema),就可以發現有些欄位變成 string 以外的型態,如 integer 或 double:
root
|-- approveDate: string (nullable = true)
...(略)...
|-- printPage: integer (nullable = true)
|-- recommendations: integer (nullable = true)
...(略)...
|-- userID: double (nullable = true)
|-- userLocation: string (nullable = true)
|-- userTitle: string (nullable = true)
|-- userURL: string (nullable = true)
|-- typeOfMaterial: string (nullable = true)
Spark SQL 初體驗
前述章節提到 DataFrame 等同關聯式資料庫(RDBMS)中的表格(table),並且提供像 SQL 一樣的介面可供查詢/運算資料(完整的 API 詳見文件),例如呼叫 select() 與 limit() 取得 1 筆資料:
df.select('*').limit(1)
但由於 Spark 分散式運算的特性,所以還得額外呼叫 collect() 將結果收回才行:
df.select(['articleID', 'commentBody']).limit(1).collect()
上述執行結果如下:
[Row(articleID='58927e0495d0e0392607e1b3', commentBody='ANY anti Trump propaganda from Gaga and my TV goes off immediately and I will never watch the NFL again. They hired her and are responsible for any unsavory political speech she may spew.')]
除了直接呼叫 DataFrame 的 API 查詢/運算資料之外, PySpark 也提供使用 SQL(Structured Query Language)進行操作,但是必須呼叫 createOrReplaceTempView() 方法將 DataFrame 轉為 temporary view, 例如以下範例將 DataFrame 轉為名稱為 comment 的 view:
df.createOrReplaceTempView('comment')
轉為 view 之後就能夠使用 Spark session 的 sql() 方法以 SQL 進行操作,例如以下範例查詢 comment 的 commentBody 欄位含有 Trump 字串的資料,並且按照 updateDate 欄位遞減排序後只取第 1 筆:
r = spark.sql('''
select articleID, commentBody
from comment
where commentBody like "% Trump %"
order by updateDate desc
limit 1
''')
上述結果同樣可以呼叫 collect() 將結果收回:
r.collect()
或者可以使用 show() 方法將結果列印出來(預設顯示 20 筆):
r.show()
上述執行結果如下:
+--------------------+--------------------+
| articleID| commentBody|
+--------------------+--------------------+
|58a7132a95d0e0247...|The Right's anti-...|
+--------------------+--------------------+
從上述結果可以看到文字過長的部分會被截斷,這種情況可以修改 show() 方法的參數為 truncate=False 以及 vertical=True :
r.show(truncate=False, vertical=True)
上述執行結果如下:
-RECORD 0-
articleID | 58a7132a95d0e02474637288
commentBody | The Right's anti-regulation furor goes back to the ultra-weathly (the Kochs, principally) gaining favor with Congress and the public through fake news; this movement is decades old. Of course the multi-billionaires want free rein in their plundering and don't want to pay a bit of tax on their profits either. This has led to Trumpism today. If you like dirty air and water and huge deficits forever, Trump and the Republicans are your team.
除了上述方法之外,也可以使用 toPandas() 方法將 PySpark 的 DataFrame 轉為 pandas 的 DataFrame, 如此一來就能夠使用 pandas 的各種功能進行操作:
pandas_df = r.toPandas()
以上就是用 PySpark 操作 Spark 的初體驗教學。
Happy coding!
References
https://spark.apache.org/docs/latest/api/python/index.html
https://spark.apache.org/docs/latest/api/python/user_guide/index.html