後端工程師日常不僅要跟程式、作業系統、架構搏鬥,也要跟資料庫(database)打交道。
資料庫的類型也隨著時代演變越來越多,除了 NoSQL, In-memory database 之外,面試過程最常聊到的還是關聯式資料庫(relational database management system),而且關聯式資料庫也是目前業界常見的資料儲存系統,各個公司無論規模大小或多或少都會有關聯式資料庫的存在,除此之外,關聯式資料庫也相當適合用以儲存交易(transaction)類型的資料。
因此操作關聯式資料庫需要用到的 SQL(Structured Query Language) 幾乎成為後端工程師面試時的必考題,而且考 SQL 的好處在於它是一項標準,無論你是 MySQL 還是 PostgreSQL 還是 MS SQL Server 的使用者,基本上都能夠用 SQL 進行交流。
本文來介紹經常會被問到的 SQL 面試問題吧!
練習用的資料庫
實際上有善心人士提供 MySQL 練習用的資料庫,可以給大家學習如何使用各種 SQL 語法,這個 sample database 是模擬一個公司儲存的產品、員工、客戶等資料的資料庫,雖然是模擬資料但足夠讓人學習各式各樣的 SQL 語法及MySQL 的功能,詳見 用 MySQL Sample Database (test db) 學習 SQL 。
本文範例主要以該練習資料庫進行。
查詢資料 / 撈資料
查詢資料(或稱撈資料)是後端工程師日常開發、數據分析都會遇到的工作,因此查詢資料相關的面試題目是最常見的題型,光是 SELECT 就有相當多可以考的,例如:
- 子查詢 Subquery
- JOIN 多張資料表
- INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN 的差異
- 聚合運算(Aggregation)
- HAVING 語句(HAVING clause)
- Window Function
這些題型不僅可以單考,還可以合在一起考,相當考驗基礎功之外,也很考驗面試者臨場拆解題目一步步寫出答案的能力。
如果想瞭解自己夠不夠熟 SELECT 語句(clause)的話,可以查閱 MySQL SELECT Statement 文件,查看自己是否對於 SELECT 可以搭配的語句都理解其作用,例如下圖中的 WHERE, GROUP BY, HAVING 以及 WINDOW 等等。

子查詢 Subquery
子查詢是 1 個 SELECT 包含多個 SELECT 查詢的情況,例如 Leetcode Customers Who Never Order 就是 1 個經典的 subquery 題目:
SELECT Name FROM Customers WHERE Id NOT IN (
SELECT DISTINCT CustomerId FROM Orders
);
JOIN 多張資料表
JOIN 資料表是常用的功能之一,所以面試時也多半會考,簡單的題目可能就像 Leetcode Combine Two Tables 只需要 JOIN 2 張資料表,困難一點就需要 JOIN 多張資料表。
JOIN 範例:
SELECT
FirstName, LastName, City, State
FROM Person
JOIN Address
ON Person.PersonId = Address.PersonId;
INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN 的差異
各種不同 JOIN 的差異幾乎是一定會被問到的題目,可以用數學集合熟記它們的差異:
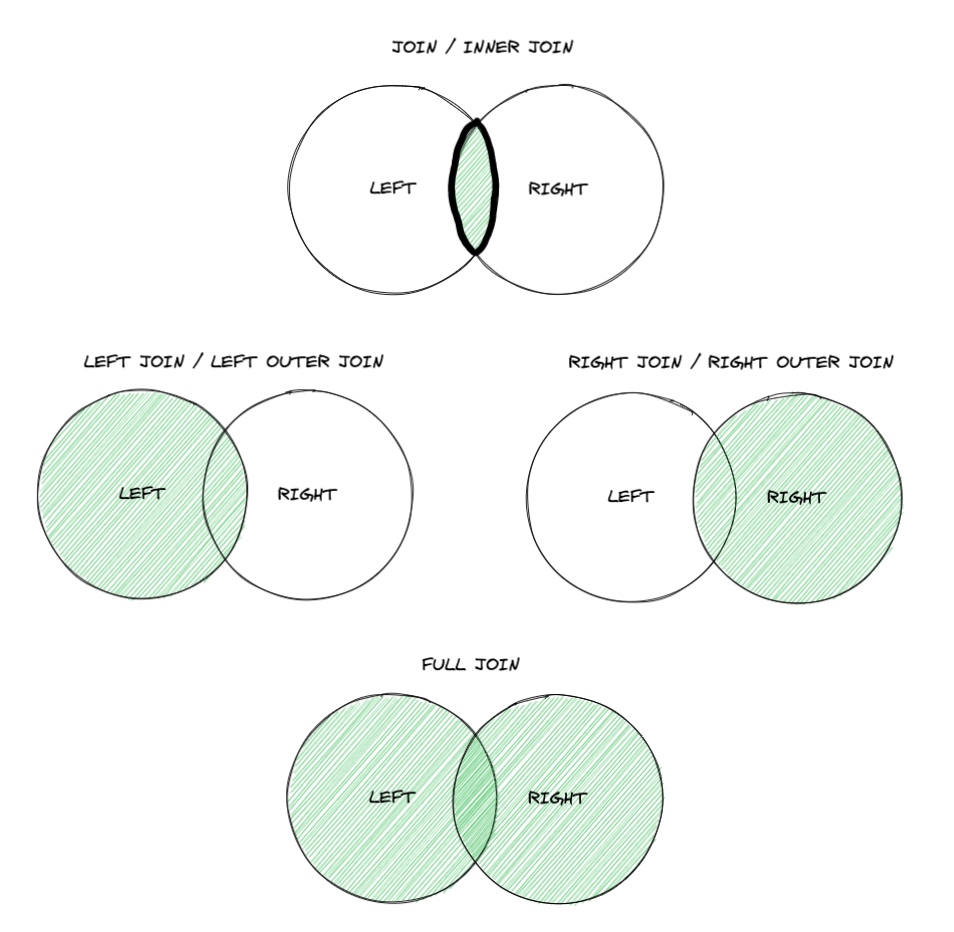
各種不同的 JOIN 自己也要實際操作過,才會有更深度的理解。
聚合運算(Aggregation)
Aggregation 是對數據進行聚合運算,例如總和、平均值、最大值和最小值等,這些可以使用聚合函數執行,如 SUM、AVG、MAX 和 MIN 等。
通常聚合運算也會搭配 GROUP BY 一起考,如下列計算每個地區消費者的平均消費金額的 SQL 範例:
SELECT location, AVG(order_value) AS avg_order_value
FROM tx
GROUP BY
location;
HAVING 語句
聚合運算之後,如果要進一步過濾資料,就得使用 HAVING 語句,例如下列計算每個地區消費者的平均消費金額大於等於 500 的 SQL 範例:
SELECT location, AVG(order_value) AS avg_order_value
FROM tx
GROUP BY
location
HAVING
avg_order_value >= 500;
The HAVING clause, like the WHERE clause, specifies selection conditions. The WHERE clause specifies conditions on columns in the select list, but cannot refer to aggregate functions. The HAVING clause specifies conditions on groups, typically formed by the GROUP BY clause. The query result includes only groups satisfying the HAVING conditions. (If no GROUP BY is present, all rows implicitly form a single aggregate group.)
也因為 HAVING 與 WHERE 語句都有過濾資料的作用,所以 2 者差異經常也是會聊到的問題。簡而言之, WHERE 語句作用於 SELECT 時,用於過濾符合條件的資料,但不包括聚合運算的部分, HAVING 作用發生於聚合運算之後,用於過濾聚合運算產生的 groups, 所以通常都接在 GROUP BY 之後。
Leetcode 的 Classes More Than 5 Students 就是經典的 HAVING 題目。
Window Function
WINDOW 語句通常用於計算排名、移動平均值和累積值等,經常會搭配 WINDOW functions 使用。
WINDOW Function 使用 OVER 子句指定用於分組的欄位和排序欄位:
例如,以下 SQL 使用 ROW_NUMBER() 將員工按照 hire_date 從最早開始進行編號,挑出最資深的前 10 名員工:
SELECT *, ROW_NUMBER() OVER (ORDER BY hire_date ASC) AS "no" FROM employees
LIMIT 10;
上述 SQL 其實就是以下的簡化:
SELECT *, ROW_NUMBER() OVER w AS "no"
FROM employees
WINDOW w AS (ORDER BY hire_date ASC)
LIMIT 10;
執行範例:
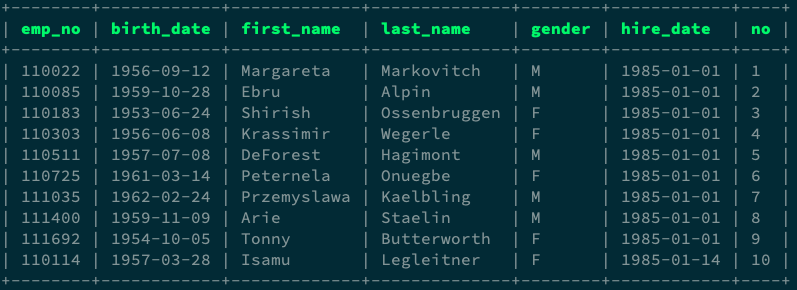
如果想對資料集進行分組運算,例如計算每個部門前 3 名高薪的員工,單用 GROUP BY 較難辦到, GROUP BY 較適合按照條件聚合區塊的運算,例如計算每個地區消費者的平均消費金額、每個部門的平均薪資等等。
但如果是計算每個部門前 3 名高薪的員工這種情況,就比較適合使用 PARTITION BY 。
PARTITION BY 與 GROUP BY 相似,但它的主要區別在於 GROUP BY 用於對整個資料集進行分組後聚合運算,而 PARTITION BY 則是用於將資料集分成多個分區,每個分區可以有不同的分析計算方式。
例如計算每個部門前 3 名高薪的員工的 SQL,每個分區會因為不同的 partition 有自己的排名 RANK() :
SELECT * FROM (
SELECT b.dept_no, a.emp_no, a.salary, rank() over w as r
FROM salaries a
JOIN current_dept_emp b
ON a.emp_no = b.emp_no
WINDOW w AS (
PARTITION BY b.dept_no
ORDER BY a.salary DESC
)
ORDER BY b.dept_no ASC, a.salary DESC) x
WHERE x.r <= 3;
執行結果範例:
+---------+--------+--------+---+
| dept_no | emp_no | salary | r |
+---------+--------+--------+---+
| d001 | 466852 | 145128 | 1 |
| d001 | 89825 | 143644 | 2 |
| d001 | 466852 | 143086 | 3 |
| d002 | 413137 | 142395 | 1 |
| d002 | 237069 | 140742 | 2 |
| d002 | 413137 | 138916 | 3 |
| d003 | 421835 | 141953 | 1 |
| d003 | 421835 | 138884 | 2 |
| d003 | 421835 | 135543 | 3 |
| d004 | 430504 | 138273 | 1 |
| d004 | 474176 | 137563 | 2 |
| d004 | 430504 | 136286 | 3 |
| d005 | 13386 | 144434 | 1 |
| d005 | 419748 | 140784 | 2 |
| d005 | 13386 | 140142 | 3 |
| d006 | 472905 | 132103 | 1 |
| d006 | 472905 | 129665 | 2 |
| d006 | 472905 | 129015 | 3 |
| d007 | 43624 | 158220 | 1 |
| d007 | 43624 | 157821 | 2 |
| d007 | 254466 | 156286 | 3 |
| d008 | 425731 | 130211 | 1 |
| d008 | 425731 | 128783 | 2 |
| d008 | 447817 | 127633 | 3 |
| d009 | 18006 | 144866 | 1 |
| d009 | 98169 | 144088 | 2 |
| d009 | 96957 | 143950 | 3 |
+---------+--------+--------+---+
WINDOW function 也可以拿來做移動平均值或累計值的計算,例如下列測試資料:
CREATE TABLE sales (
sale_id SERIAL PRIMARY KEY,
customer_name VARCHAR(50),
product_name VARCHAR(50),
sale_date DATE,
sale_amount NUMERIC(10, 2)
);
INSERT INTO sales (customer_name, product_name, sale_date, sale_amount) VALUES
('Alice', 'Product A', '2022-01-01', 100.00),
('Bob', 'Product B', '2022-01-01', 200.00),
('Alice', 'Product A', '2022-01-02', 150.00),
('Charlie', 'Product C', '2022-01-02', 300.00),
('Alice', 'Product B', '2022-01-03', 250.00),
('Bob', 'Product C', '2022-01-03', 350.00),
('David', 'Product A', '2022-01-04', 100.00),
('Charlie', 'Product B', '2022-01-05', 200.00),
('Eve', 'Product C', '2022-01-05', 300.00),
('David', 'Product A', '2022-01-06', 250.00);
要計算每日移動平均銷售額的話,先把每日銷售額用 GROUP BY 加總之後,再搭配 WINDOW Function 計算每一列與前一列的的平均值(也就是 ROWS BETWEEN 1 PRECEDING AND CURRENT ROW 的部分):
SELECT
sale_date,
AVG(sale_amount) OVER (ORDER BY sale_date ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS running_avg
FROM (
SELECT sale_date, SUM(sale_amount) as sale_amount
FROM sales
GROUP BY sale_date
) x
ORDER BY
sale_date ASC;
執行結果:
+------------+-------------+
| sale_date | running_avg |
+------------+-------------+
| 2022-01-01 | 300.000000 |
| 2022-01-02 | 375.000000 |
| 2022-01-03 | 525.000000 |
| 2022-01-04 | 350.000000 |
| 2022-01-05 | 300.000000 |
| 2022-01-06 | 375.000000 |
+------------+-------------+
關於 WINDOW function 其實還有很多用法,詳見 Window Function Concepts and Syntax 。
中位數
另一種工作上實用而且面試時常見的題目就是「找中位數(median)」,之所以它很實用是可以查看數值分佈概況而且能避免極端值的影響,例如薪水分佈看中位數是最合理的,可以代表 50% 的人薪水在什麼水準之下。
中位數的找法可以用 WINDOW function, 也可以不用 WINDOW function, 原理都是對資料排序後做編號,編號位於中間的值就是中位數。
我們以 MySQL test db 中的 salaries 資料表作為範例,在此介紹 2 種 MySQL 找到中位數的方法:
不使用 WINDOW function
SET @rowindex := -1;
SELECT
AVG(s.salary) as Median
FROM
(SELECT @rowindex:=@rowindex + 1 AS rowindex,
salaries.salary AS salary
FROM salaries
ORDER BY salaries.salary) AS s
WHERE
s.rowindex IN (FLOOR(@rowindex / 2), CEIL(@rowindex / 2));
解釋一下上述 SQL 的意思:
- 先設定 1 個變數稱為
rowindex - 接著按照 salary 排序查詢所有的 salary 以及
rowindex, 在查詢的過程中 rowindex 會一直遞增,其值會是 0 開始到 (資料筆數 - 1) 結束 - 進一步查詢第 2 步產生的結果,找出
rowindex介於中間的資料列,也就是s.rowindex IN (FLOOR(@rowindex / 2), CEIL(@rowindex / 2))的部分,因為有可能資料總數是偶數,例如 4 筆,所以中位數會位於第 2 與第 3 筆之間,所以此處才分別使用FLOOR以及CEIL分別找出上下界,如果資料總數是奇數,上下界就會相同 - 將第 3 步的資料列作平均,就會是中位數
使用 WINDOW function - PERCENT_RANK()
SELECT * FROM (
SELECT
salary,
ROUND(PERCENT_RANK() OVER (ORDER BY salary), 2) AS pct_rank
FROM
salaries
) AS d
WHERE
d.pct_rank = 0.5
ORDER BY
salary ASC
LIMIT 1;
使用 WINDOW function 的方式就相對簡潔,只需要找到 PERCENT_RANK() 為 0.5 的資料即可, 0.5 代表 50% 的位置,也就是中位數。
PERCENT_RANK() 的公式為 (排名 - 1) / (資料總筆數 - 1), 所以 0 代表最小值, 1 代表最大值 。
不過這個方法沒有方法 1 來得準確,有 2 點原因:
PERCENT_RANK()算出來的中位數位置的值,不一定是 0.5, 舉 4 筆資料為例,中位數會位於第 2 筆與第 3 筆之間,而這 2 筆的PERCENT_RANK()會是 1/3 與 2/3, 所以方法 2 的 SQL 會找不到PERCENT_RANK()會可能因為公式算出會在 0.5 左右 的值,例如中位數可能位於0.4999與0.5001之間,為了取 1 個接近值,只好用ROUND()做 rounding 取出值為 0.5 的結果,但該值僅是 1 個接近值,並不是準確的解答
效能分析
如何對 SQL 進行效能分析也經常是面試時會問到的題目,這是由於 SQL 如果沒有寫好就可能造成 slow query, 不僅查詢時間久(通常原因是 full table scan),也可能造成資料庫系統 CPU 資源忙碌,而無法回應其他查詢要求,導致整體效能下降。
所以任何 SQL 在開發時都應該用 EXPLAIN 語句先行檢驗一次,查看是否有 Full Table Scans 的問題, MySQL 與 PostgreSQL 都有提供 EXPLAIN 的功能,讓開發者檢驗資料庫打算如何執行我們所寫的 SQL 。
MySQL: MySQL :: MySQL 8.0 Reference Manual :: 8.8.1 Optimizing Queries with EXPLAIN
PostgreSQL: PostgreSQL: Documentation: 15: EXPLAIN
另外,也要知道資料庫都有提供 slow query log 可以幫助我們抓到系統中正在發生的 slow query, 以幫助我們找到資料庫效能問題。
索引(Index)
資料表索引(Index)是一種以空間換取時間的技術,前述的 full table scan 問題,如果經過各種嘗試都無法解決的話,就可以考慮是否加上適當的資料表索引,以加速資料庫查詢的速度。
但千萬要記住,並不是所有欄位都加上索引就能保證資料庫的查詢速度快,索引越多,會造成資料寫入越慢,這是由於每新增 1 筆資料,所有的索引都要進行更新的緣故,因此增加索引必須小心謹慎。
以下是針對 customer 表的 name 欄位前 10 個字元建立索引的範例:
CREATE INDEX part_of_name ON customer (name(10));
除了針對單一欄位建立索引之外,也可以視需求針對多個欄位一起建立索引,例如:
CREATE INDEX idx1 ON t1 ((col1 + col2));
最後,建立索引時也要考慮索引的類別,以 MySQL 為例,索引的類別分為 B-tree 與 Hash 2 種,這 2 種有各自適合的情境,譬如某些不重複的欄位,就適合使用 Hash 作為索引,不過 Hash 索引無法進行範圍查詢和排序,因此要考慮清楚。
總結
除了熟悉你所使用的關聯式資料庫與 SQL 之外,面試前也可以刷一下 Leetcode 的資料庫題,準備起來也比較有效率。
References
MySQL :: MySQL 8.0 Reference Manual :: 13.2.13 SELECT Statement
MySQL :: MySQL 8.0 Reference Manual :: 12.21.2 Window Function Concepts and Syntax
MySQL :: MySQL 8.0 Reference Manual :: 8.2.1.23 Avoiding Full Table Scans