用 Google Sheets 製作簡易爬蟲
Posted on Dec 17, 2017 in Google 試算表 by Amo Chen ‐ 2 min read
Google Sheets 有內建幾個能夠用來擷取網頁資料的函式(function) ,例如 IMPORTXML , IMPORTHTML , IMPORTDATA 等等。
如果只是簡單的需求,不妨可以考慮用這些函數來幫忙擷取資料。
本文用政府資料開放平臺的網頁及資料及進行示範:
IMPORTDATA
如果需要載入 .csv , .tsv 2 種格式的資料時,可以利用 IMPORTDATA 。
使用的方法很簡單,只要在 IMPORTDATA 函式放入資料連結即可,例如要載入 YouBike 資料的話,只要在儲存格輸入:
=IMPORTDATA("https://quality.data.gov.tw/dq_download_csv.php?nid=28318&md5_url=45daed3330c8be0e1174e2f17b961d0a")
接著等候一小段時間,就會看到資料載入在 Google Sheets 了。
IMPORTHTML
如果是需要從某個網頁上擷取表格資料,則可以使用 IMPORTHTML 。
雖然函數名稱是 IMPORTHTML 但是此函式只能夠用來擷取 <table> <ol> <ul> 3 種 HTML 標籤內的資料。
可以直接輸入 Google 提供的範例,感受一下威能:
=IMPORTHTML("http://en.wikipedia.org/wiki/Demographics_of_India","table",4)
IMPORTHTML 的語法為:
IMPORTHTML(url, query, index)
如前面所述,因為此函式只能夠用來擷取 <table> <ol> <ul> 3 種 HTML 標籤內的資料,所以第 2 個參數也只能輸入 table 或是 list ,除了 table 以外的資料就是 list 。
index 則是第幾個的意思,例如要抓取頁面上第 4 個表格就得輸入:
=IMPORTHTML("網址", "table", 4)
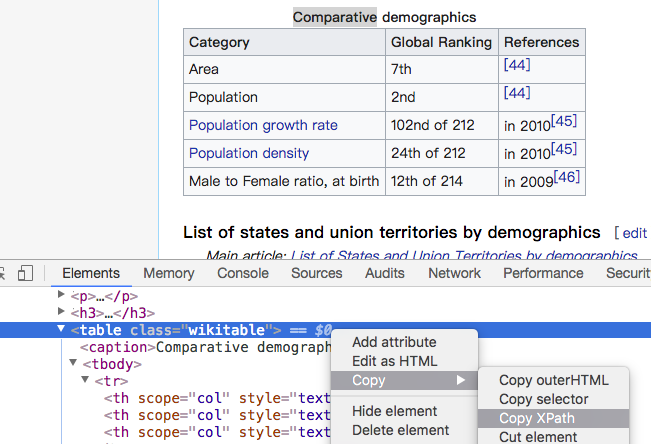
如果想知道表格在頁面上是第幾個,可以利用 右鍵 > 檢查元素 ,然後在 table 元素(elemnet)上再點 右鍵 > Copy > Copy Xpath ,然後找個記事本貼上剛剛得到字串,會得到跟以下結果類似的字串:
//*[@id="mw-content-text"]/div/table[6]
上述範例的 6 就是 index 要填的值。
p.s. list 就無法這樣得到 index ,因為 list 可能有 ol, ul 2 種,所以 index 會算不準。
IMPORTXML
因為 IMPORTHTML 有著先天性的限制,如果要做到更彈性的擷取網頁資料,可以使用 IMPORTXML ,然後搭配 IMPORTHTML 所提到的 Copy Xpath 就可以擷取網頁上的任意資料。
IMPORTXML 的語法:
IMPORTXML(url, xpath_query)
例如要抓取 新北市公共自行車租賃系統(YouBike) 的網頁標題可以輸入:
=IMPORTXML("https://data.gov.tw/dataset/28318", "//*[@id='node-28318']/div[1]/div/h1")
p.s. Copy Xpath 會含有雙引號 " ,記得取代成單引號 ' 再放入 IMPORTXML 中,否則會出現 #ERROR!
如果要抓取大量資料,建議不要使用此種方式,因為 Google Sheets 並無法控制抓取的速率,很可能會在短時間內對對方的網站發起大量要求(request),變成一種變相的攻擊行為
參考資料
https://support.google.com/docs/answer/3093335
https://support.google.com/docs/answer/3093339
https://support.google.com/docs/answer/3093342