實戰 Python 效能分析 - 從 cProfile 到 py-spy
Posted on Dec 9, 2021 in Python 程式設計 - 高階 by Amo Chen ‐ 5 min read
Python 應用(application)相較於 Go, C 這類語言所寫的應用,前者執行效率較慢是公認問題,不過 Python 的易用性也相對地提升開發速度,甚至其 batteries included 的哲學以及豐富的生態系也能夠減少重複造輪的情況,大幅縮短從概念到產品的實現路徑。
至於執行效率慢的問題,其實可以透過多種手段進行改善,譬如進行分散式、多執行緒(multithreading)、多行程(multiprocessing)、改善演算法,或以其他較高效率的語言為 Python 進行擴充(例如 ctypes 模組),雖然無法保證一定能夠像 Go, C 這類語言同樣高效,但也能夠將效率提升到可接受的程度以上。
但在處理真正的效率問題之前,絕大多數可能是我們沒有以正確有效率的方式撰寫 Python 應用,而導致其執行效率較差,並且將問題怪罪於 Python 本身。
因此如何剖析 Python 程式,並且找到隱藏在其中的效率問題,是一門相當重要的課題,本文將從介紹 cProfile 模組開始,並以實際範例找出 Python 程式中的問題點,並使用 py-spy 工具更近一步精準定位問題所在,以提高找出問題的效率。
本文環境
$ pip install pandas==1.0.3 snakeviz py-spy
資料集
本文需要使用以下資料集作為範例程式所需要的資料集:
Daily Financial News for 6000+ Stocks
範例程式
以下是本文的範例程式,該程式會載入資料集中的 raw_partner_headlines.csv 檔,統計該資料集中 headline 欄位中含有 To New High 的美股代號以及出現該美股代號出現次數,並在最後由高至低將超過 5 次以上的美股代號依序列印。
import re
import pandas as pd
from collections import Counter
def load_data():
return pd.read_csv(
'<path to>/raw_partner_headlines.csv',
chunksize=100
)
def main():
counter = Counter()
for df in load_data():
for r in df.itertuples():
if re.search(r'To New High', r.headline):
counter[r.stock] += 1
for stock, count in sorted(
counter.items(),
key=lambda x: x[1],
reverse=True
):
if count >= 5:
print(stock, count)
main()
上述範例執行結果如下,該範例大約會耗時 1 分鐘以上的時間執行:
$ time python test.py
ULTA 9
ALK 5
YY 5
python test.py 70.01s user 7.17s system 100% cpu 1:17.00 total
cProfile 模組
cProfile 是 Python 內建的效能分析模組,該模組提供 2 種方式讓開發者可以對 Python 程式進行效能分析:
上述 2 種方法差別在於實作方式, cProfile 是以 C 語言實作的 Python 擴充(extension), 適合用來剖析長時間執行的 Python 程式,不僅效能較好,也是 Python 官方推薦的方式;而 profile 則是由 Python 實作的模組,效能較差,一般不推薦使用 profile 對 Python 程式進行分析。
使用 cProfile 模組的方式相當簡單,只要在執行 Python 指令時加上 -m cProfile 即可。
以下為對前文範例程式進行剖析(profiling)的指令:
$ python -m cProfile test.py
上述指令執行到最後會列印效能分析的結果,如下所示:
...
126019093 function calls (124921197 primitive calls) in 111.419 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 <__array_function__ internals>:2(<module>)
110737 0.102 0.000 0.380 0.000 <__array_function__ internals>:2(concatenate)
上述報表主要有 6 個重點:
- 執行時間 111.419 秒
- 排序依據為 standard name, 也就是 filename:lineno(function) 欄位
- 每個 function 呼叫了幾次,也就是
ncalls的值 - 每個 function 總計花費多少時間,但不包括該 function 所呼叫其他 function 的時間,也就是
tottime的值 - 每個 function 總計花費多少時間,包括該 function 所呼叫其他 function 的時間,也就是
cumtime的值 - 2 個 percall 則分別是
tottime以及cumtime各自除以ncalls的值,也就是平均每次呼叫會花費的時間
預設的排序方式通常很難一眼看出問題,因此我們會更改排序方式,將按照 cumtime 的時間排序,通常時間花費最久的 function 就是問題點,值得我們 追查:
$ python -m cProfile -s cumulative test.py | less
上述指令多了 -s cumulative 代表以 cumtime 遞減排序(更多排序選項詳見官方文件):
...
126019099 function calls (124921203 primitive calls) in 112.626 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
19157/1 7.448 0.000 113.576 113.576 {built-in method builtins.exec}
1 0.000 0.000 113.576 113.576 test.py:1(<module>)
1 2.707 2.707 113.179 113.179 test.py:14(main)
18457 0.022 0.000 82.398 0.004 parsers.py:1105(__next__)
18457 0.089 0.000 82.376 0.004 parsers.py:1160(get_chunk)
18457 0.217 0.000 82.287 0.004 parsers.py:1131(read)
18456 0.141 0.000 44.636 0.002 frame.py:414(__init__)
18456 0.181 0.000 44.408 0.002 construction.py:213(init_dict)
18457 0.259 0.000 36.784 0.002 parsers.py:2035(read)
18457 28.631 0.002 35.912 0.002 {method 'read' of 'pandas._libs.parsers.TextReader' objects}
上述文字形式的分析報表通常會過於冗長,不便於閱讀,推薦使用 SNAKEVIZ 以視覺化的方式閱讀該報表,因此我們需要透過指令將文字報表輸出成檔案,以下指令用 -o 參數將報表輸出至 test.prof 檔案中:
$ python -m cProfile -o test.prof test.py
接著,使用 snakeviz 讀取該報表:
$ snakeviz test.prof
上述指令將會以瀏覽器(browser)打開圖表:
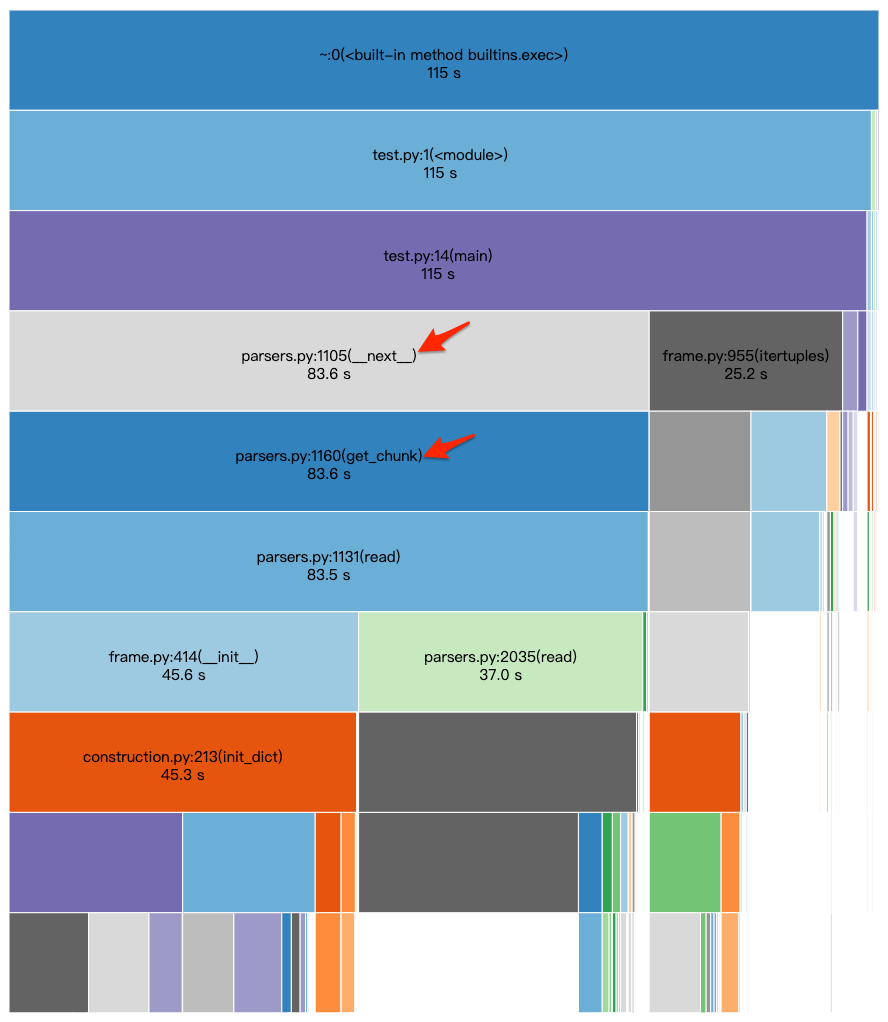
上圖可以看到 parsers.py:1105(__next__) 花費約 83.6 秒,佔整個 main() 執行時間 115 秒的 72% 左右,而 __next__ 為 Python 迴圈可能呼叫的方法,該方法又進一步呼叫 get_chunk ,所以可以看到 get_chunk 的 cumtime 與 __next__ 的 cumtime 幾乎一模一樣。
從這些線索就可以推測應該是程式碼 for 迴圈的部分相當花時間,如果進一步查詢 get_chunk 的資訊(如下圖所示),可以發現其 ncalls 值為 18457, 雖然 percall 只有 0.004 秒,但因為呼叫次數相當多,最終還是對執行時間產生影響,如果能夠降低 ncalls 就能有效縮短執行時間。

搭配 get_chunk 的線索,幾乎可以確定是範例程式中 chunksize=100 設定太小的緣故,可以試著將 chunksize 調到 1000 試試:
import re
import pandas as pd
from collections import Counter
def load_data():
return pd.read_csv(
'<path to>/raw_partner_headlines.csv',
chunksize=1000
)
def main():
counter = Counter()
for df in load_data():
for r in df.itertuples():
if re.search(r'To New High', r.headline):
counter[r.stock] += 1
for stock, count in sorted(
counter.items(),
key=lambda x: x[1],
reverse=True
):
if count >= 5:
print(stock, count)
main()
接著再重複一次 profiling 的過程,並且查看執行時間是否下降:
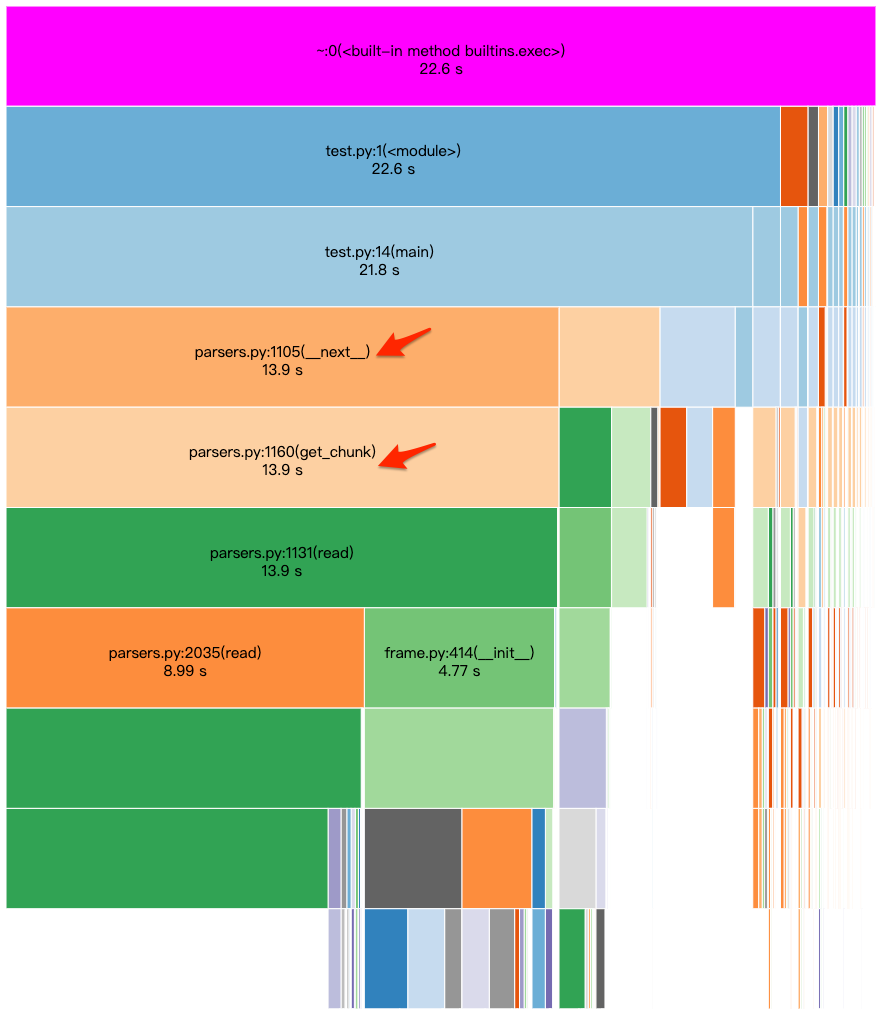
從上述結果顯示將 chunksize 調整為 1000 之後,執行時間就降到 22.6 秒,而且 for 迴圈的部分也縮短為 13.9 秒,如果進一步查詢 ncalls, 也可發現呼叫次數縮短到 1847 次,如下圖所示:

行文至此,可以發現 cProfile 最多只能幫助我們追查到 function level 的效率問題,具體是 function 內的哪一行有問題,還是需要一些經驗進行推敲,如果能夠更具體定位到哪一行,將會更加有效率,這時可以使用類似 py-spy 等能夠逐行(line by line)分析的 profiler 幫忙。
py-spy
py-spy 是一套相當成熟的 sampling profiler, 預設每秒會對程式取樣 100 次,其運作原理是取樣讀取 Python 的記憶體,藉此了解 Python 當時正在執行什麼工作(從 call stack 能夠得知),所以執行時間越久的部分,越容易被取樣到,藉此達成分析的功能。
py-spy 除了支援 thread 的 profiling 之外, 也支援 multiprocessing 的 profiling, 也能夠針對執行中的 Python process 進行 profiling, 是相當值得學習如何使用的效能分析工具,更多 py-spy 介紹詳見官方文件。
以下指令用 py-spy 對範例程式進行效能分析,並將結果輸出至 profile.svg :
$ sudo py-spy record -o profile.svg -- python test.py
Password:
py-spy> Sampling process 100 times a second. Press Control-C to exit.
...
p.s. macOS 需要使用 sudo 才能執行
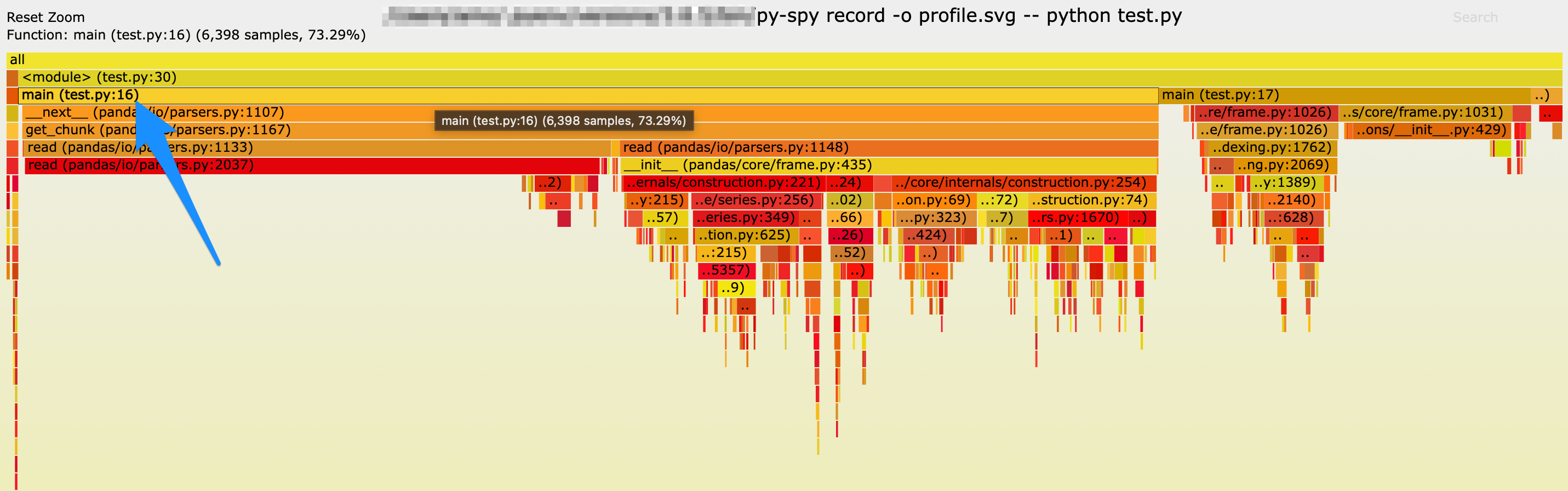
上述指令完成之後會同樣會打開瀏覽器,並以火焰圖(flame graph)形式呈現分析結果,如下圖所示,從圖中藍色箭頭所指可以看到 py-spy 清楚地顯示出 test.py 第 16 行的部分佔了絕大多數的執行時間,而 16 行剛好就是 for 迴圈的部分,相較於 cProfile 的分析結果而言又更加明確。
總結
雖然 cProfile 有其不便的地方,但卻是 Python 內建提供的模組,不需額外安裝其它套件,同時該模組也是學習 Python 效能分析很好的開始,是相當值得閱讀學習的模組,在了解其原理之後,對於其他工具也會相當好上手。
另外,實務上效能分析與改善的過程通常會較為複雜一點,本文所提供的範例只是為了簡化過程而設計,本文僅是扮演一個引路的角色,基本上還是需要仰賴多次的練習才能夠提升效能分析與改善的技能。
以上!
Happy coding!
References
https://docs.python.org/3/library/profile.html
https://github.com/benfred/py-spy