資料科學(data science)的興起以及日益增長的大資料的分析需求,傳統以資料列為導向(row-oriented)的儲存方式逐漸顯現其未逮之處,因此以欄位為導向(column-oriented, 或稱 columnar)的儲存方式應運而生,其中 Apache Parquet 是相當知名的 columnar 檔案格式,也能夠搭配 Hive, Spark 等知名的 Apache 開源專案使用。
本文將介紹 Apache Parquet 儲存格式,並且透過實際操作理解 Parquet 格式與其奧妙之處。
本文環境
- macOS 11.6
- homebrew
- Python 3.7
- pandas 1.0.3
- pyarrow 6.0.1
- parquet-cli
$ pip install pyarrow pandas
$ brew install parquet-cli
Row-oriented vs. Columnar
傳統的關聯式資料庫(Relational Database Management System, RDBMS)或者 CSV 等檔案格式,就是以資料列為導向的儲存方式,例如以下 CSV 格式的資料,每 1 列都代表 1 筆資料,十分易於理解:
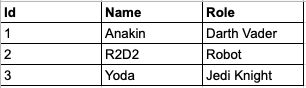
以資料列為導向的儲存方式的應用情境,相當適合 Web-based system, APP 等相關資訊系統的應用,例如常見的使用者資料表(table),我們能夠為每 1 筆使用者資料設計 Id 欄位以及相關欄位或者其他資料表,並透過 Id 欄位索引(index)並取得與特定使用者 Id 相關的資料。
而以欄位為導向(columnar)的儲存方式,大致可以想像每 1 列都是某欄位的所有值,前述 CSV 範例轉換成 columnar 形式的話,就像以下範例(本範例為了易於理解經過簡化,實際上 Apache Parquet 格式更加複雜一點):
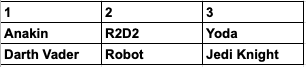
上述格式中,同 1 欄的資料,就會是同 1 筆資料,例如上圖中的第 2 欄就等同於前述 CSV 資料列中的 2,R2D2,Robot 。
可以想見欄位為導向(columnar)的儲存方式,如果要取得特定 Id 的所有資料,相對沒有以資料列為導向的儲存方式來的方便(各位可以自行想像如何從上述資料中取得第 2 欄的所有資料,並聚合成 1 筆資料)。
不過 columnar 的儲存方式卻十分適合資料分析的用途。
譬如進行資料分析時,一般不會以所有欄位的資料進行分析,僅會取需要的數個欄位進行分析,對 columnar 的儲存方式來說,可以很方便地選取所需要的欄位,例如前述範例,只要讀取第 1 行與第 3 行,就能夠取出 Id 與 Role 的所有資料,而以資料列為導向的儲存格式,就必須走訪每 1 列才能取出所需要的欄位值。
當然兩者都能夠運用在資料分析上,但是當資料到達一定規模時,選擇 columnar 的儲存格式將會更具效率。
測試資料
本文使用以下資料集進行操作,該格式為 CSV 格式,下一章節將實際操作如何將 CSV 檔案轉換為 Apache Parquet 格式。
https://www.kaggle.com/aashita/nyt-comments?select=CommentsApril2017.csv
Apache Parquet 資料格式簡介
Apache Parquet 可說是為了能夠高效資料處理(data processing)而創造的一種檔案格式,因此 Apache Parquet 的結構(structure)設計上就有考慮批次(batch)載入、壓縮(compression)儲存、平行運算等需求,其檔案結構圖如下所示:
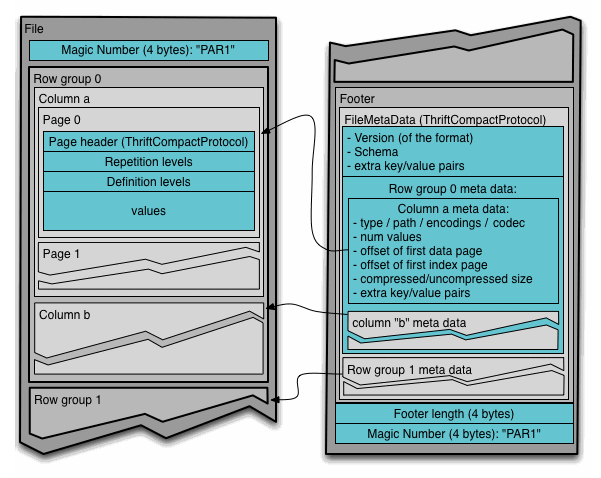
乍看有些複雜,不過搭配官方文件就能夠理解,首先是 Parquet 檔案前 4 bytes 是其魔術數字(magic number),所以可以用 hexdump 指令列印前 4 個 bytes, 這 4 個 bytes 剛好會是 ASCII 編碼中的 PAR1 .
$ hexdump -c -n 4 test.parquet
0000000 P A R 1
0000004
剩下的部分,就交由後續章節以範例搭配文字進行說明。
CSV to parquet
pandas 內建支援 Apache Parquet 格式轉換,只要呼叫 DataFrame 的 to_parquet() 方法即可。
以下範例將測試資料集 CommentsApril2017.csv 轉換為 Apache parquet 格式:
>>> import pandas as pd
>>> df = pd.read_csv('<path to>/CommentsApril2017.csv')
>>> df.to_parquet('<path to>/test.parquet')
轉換完成之後,接下來的章節會用 parquet-cli 套件讀取 Apache Parquet 檔案相關的結構與資訊。
p.s. 除了 pandas 之外,也可以用 pyarrow 操作 parquet 檔案
探訪 Apache Parquet 檔案結構
Metadata & Row group
Apache Parquet 檔案中會存有 3 種關於資料的 metadata, 分別是:
- file metadata
- column (chunk) metadata
- page header metadata
可以使用以下指令讀取 parquet 檔案的 metadata:
$ parquet meta test.parquet
上述指令結果如下圖所示:
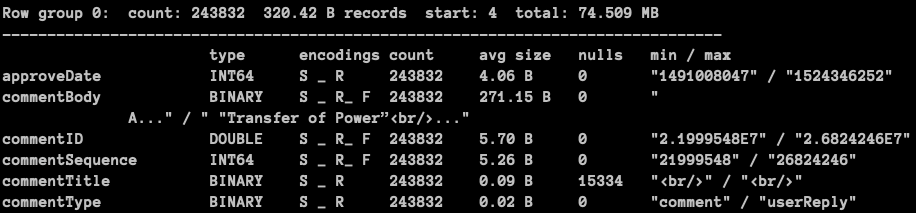
從上圖可以看到 metadata 存有各個欄位的型別(type), 編碼(encoding), 個數(count) 等資訊,其中值得注意的是 Row group 0: count: 243832 320.42 B records start: 4 total: 74.509 MB 一行,該行中的 Row group 是 parquet 檔案結構中相當重要的存在。
- Row group: A logical horizontal partitioning of the data into rows. There is no physical structure that is guaranteed for a row group. A row group consists of a column chunk for each column in the dataset.
- Column chunk: A chunk of the data for a particular column. These live in a particular row group and is guaranteed to be contiguous in the file.
Parquet 可能會將所有欄位都切割成數個區塊(切割區塊時不可以破壞欄位值的次序),這些區塊就被稱為 column chunk, 例如欄位 A, B 都有 500 個值,那麼 A, B 可能會被切割成 2 個各 250 大小的 A1, A2 以及 B1, B2 共 4 個區塊(column chunk), 而其中 A1, B1 會組成 1 個 row group, A2, B2 則組成另一個 row group:
- row group 0
- A1 (column chunk)
- B1 (column chunk)
- row group 1
- A2 (column chunk)
- B2 (column chunk)
這樣切割分組所帶來的好處,讓我們能夠以 row group 為單位進行平行運算,因為每個 row group 都存有所有欄位的一部分(也就是 column chunks), 所以能算好一部分的結果,最後再以 row group 為單位將結果合併。
所以 parquet 檔案的結構大致就像以下的層級:
- parquet file
- row group 0
- column A chunk 0
- column B chunk 0
- ...
- row group 1
- column A chunk 1
- column B chunk 1
- ...
- row group N
- column A chunk N
- column B chunk N
- ...
型別(type) & Schema
考慮到資料儲存空間的利用效率,Apache Parquet 採用二進制(binary)的形式儲存資料,而且設計多種資料型別(type),用以儲存各種類型的資料:
- BOOLEAN - 布林值,大小 1 bit
- INT32 - 整數,大小 32 bit
- INT64 - 整數,大小 64 bit
- INT96 - 整數,大小 96 bit
- FLOAT - 浮點數,大小 32 bit
- DOUBLE - 倍精數,大小 64-bit
- BYTE_ARRAY - 位元組陣列,大小依陣列長度而定
由於這些型別有其規定的大小,如果是儲存相同的資料的條件下,以 Apache Parquet 格式儲存,會比 JSON 格式更加節省儲存空間。
另外, Apache Parquet metadata 中也存有資料的 schema 資訊,例如:
Schema:
message schema {
optional int64 approveDate;
optional binary commentBody (STRING);
optional double commentID;
optional int64 commentSequence;
optional binary commentTitle (STRING);
optional binary commentType (STRING);
optional double createDate;
optional int64 depth;
optional boolean editorsSelection;
optional double parentID;
optional binary parentUserDisplayName (STRING);
optional binary permID (STRING);
optional binary picURL (STRING);
optional double recommendations;
optional double recommendedFlag;
optional double replyCount;
optional double reportAbuseFlag;
optional int64 sharing;
optional binary status (STRING);
optional double timespeople;
optional double trusted;
optional int64 updateDate;
optional binary userDisplayName (STRING);
optional int64 userID;
optional binary userLocation (STRING);
optional binary userTitle (STRING);
optional binary userURL (STRING);
optional int64 inReplyTo;
optional binary articleID (STRING);
optional binary sectionName (STRING);
optional binary newDesk (STRING);
optional double articleWordCount;
optional int64 printPage;
optional binary typeOfMaterial (STRING);
}
上述 schema 記載著每 1 筆資料的型別與欄位名稱,optional binary commentBody (STRING); 代表著欄位名稱 commentBody 是 binary 類型的字串資料,也就是前述 BYTE_ARRAY 型別,而 optional 則代表該欄位允許可有可無或者可儲存 null 值。
p.s. 除了 optional 之外,還有 required , repeated 共 3 種
前述範例是只有 1 層深度的 schema, Apache parquet 還能儲存更加複雜的巢狀(nested) schema, 例如以下範例製作 1 個存有複雜巢狀資料的 parquet 檔案:
>>> import pandas as pd
>>> df = pd.read_json(
'''
{"name": "abc", "attrs": {"sex": "male", "numbers": [1, 2, 3]}}
{"name": "def", "attrs": {"sex": "female", "numbers": [2, 3, 4]}}
''',
lines=True
)
>>> df.to_parquet('<path to>/nested.parquet')
接著以 parquet meta 指令查看 schema, 可以看到 Apache Parquet 也能夠儲存複雜的巢狀 schema:
$ parquet meta nested.parquet
message schema {
optional binary name (STRING);
optional group attrs {
optional group numbers (LIST) {
repeated group list {
optional int64 item;
}
}
optional binary sex (STRING);
}
}
The structure of the record is captured for each value by two integers called repetition level and definition level. Using definition and repetition levels, we can fully reconstruct the nested structures.
關於 Apache Parquet 如何處理巢狀 schema 的詳情,可以參考 twitter blog Dremel made simple with Parquet 一文,該文清楚說明 Apache Parquet 透過 Definition levels 處理巢狀 schema 的層級(level),另外透過 Repetition levels 處理不定長度的 repeated 欄位 schema, 因此只要結合 Definition levels 以及 Repetition levels 就能將 columnar 資料重建(reconstruct)出如 schema 所描述般的樣貌。
Page
- Page: Column chunks are divided up into pages. A page is conceptually an indivisible unit (in terms of compression and encoding). There can be multiple page types which is interleaved in a column chunk.
接著談談 page, 前文提到 Apache Parquet 的設計有考慮到儲存空間的利用效率,因此採用二進制(binary)的形式儲存資料,而為了更加優化儲存空間的利用效率, Apache Parquet 也支援對資料進行壓縮(compression)與編碼(encoding), Apache Parquet 2.4 支援以下 5 種壓縮方式:
- Snappy
- Gzip
- LZO(Lempel–Ziv–Oberhumer)
- BROTLI
- LZ4
- ZSTD(Zstandard)
而根據 Apache Parquet 文件所述,1 個 column chunk 會再被切為多個 pages, 因此各個結構由大到小的階級就如下所示:
- parquet file
- row group
- column chunk
- page
而前述所提到的壓縮(compression)與編碼(encoding)就是以 page 為單位進行,將 column chunk 切為多個 pages 的好處也是能夠以 page 為單位同時對多個 pages 進行壓縮。
截至目前為止,可以看到從 row group 到 page 都透過切分的方式,使得我們對於資料讀取與運算的過程增添平行處理的可能性,這也是為什麼 Apache Parquet 文件中如此寫到:
Unit of parallelization
- MapReduce - File/Row Group
- IO - Column chunk
- Encoding/Compression - Page
如要讀取 Parquet 檔案的 pages 資訊可以使用以下指令:
$ parquet pages test.parquet
上述指令執行結果如下:
...(略)...
Column: commentID
--------------------------------------------------------------------------------
page type enc count avg size size rows nulls min / max
0-D dict S _ 131072 8.00 B 1024.000 kB
0-1 data S R 131072 2.13 B 272.264 kB 0 "2.1999548E7" / "2.6800252E7"
0-2 data S _ 112760 8.00 B 880.945 kB 0 "2.2142652E7" / "2.6824246E7"
...(略)...
上述指令結果除了可以看到 commentID 欄位被分為多個 pages 之外,還可以看到 pages 也紀錄一些基本的資訊 count, avg size, size, rows, nulls. min/max 等等,其中 enc 代表所使用的編碼與編碼(encoding)方式,其格式為 <壓縮方法> <編碼方法>,例如 S _ 中的 S 代表使用 Snappy 壓縮, _ 則代表未使用特殊編碼方法,更詳細的代碼資訊可以參考以下 2 個 Github 連結:
至此,我們已經可以說對 Apache Parquet 有一番清楚的認識。基本上,只要能夠理解 row group, column chunk 以及 page 這 3 種重要的組成,就可以對 Apache Parquet 駕輕就熟。
其他 parquet-cli 相關指令
最後條列式介紹其他 parquet-cli 相關功能。
列印前幾行資料
$ parquet head <parquet file> -n <行數>
例如:
$ parquet head test.parquet -n 1
{"approveDate": 1491245186, "commentBody": "This project makes me happy to be a 30+ year Times subscriber... continue to innovate across all platforms, please.", "commentID": 2.2022598E7, "commentSequence": 22022598, "commentTitle": "<br/>", "commentType": "comment", "createDate": 1.491237056E9, "depth": 1, "editorsSelection": false, "parentID": 0.0, "parentUserDisplayName": null, "permID": "22022598", "picURL": "https://graphics8.nytimes.com/images/apps/timespeople/none.png", "recommendations": 2.0, "recommendedFlag": null, "replyCount": 0.0, "reportAbuseFlag": null, "sharing": 0, "status": "approved", "timespeople": 1.0, "trusted": 0.0, "updateDate": 1491245186, "userDisplayName": "Rob Gayle", "userID": 46006296, "userLocation": "Riverside, CA", "userTitle": null, "userURL": null, "inReplyTo": 0, "articleID": "58def1347c459f24986d7c80", "sectionName": "Unknown", "newDesk": "Insider", "articleWordCount": 716.0, "printPage": 2, "typeOfMaterial": "News"}
查看各欄位大小
$ parquet column-size <parquet file>
例如:
$ parquet column-size test.parquet
updateDate-> Size In Bytes: 1112122 Size In Ratio: 0.01423451
typeOfMaterial-> Size In Bytes: 1293 Size In Ratio: 1.6549642E-5
approveDate-> Size In Bytes: 989185 Size In Ratio: 0.012660989
commentSequence-> Size In Bytes: 1281710 Size In Ratio: 0.016405137
...(略)...
References
https://parquet.apache.org/documentation/latest/
https://arrow.apache.org/docs/python/index.html
https://blog.twitter.com/engineering/en_us/a/2013/dremel-made-simple-with-parquet